By Rachel Nuwer, Office of Engineering Communications

Researchers used machine learning to create the first large-scale, data-driven study to illuminate how culture affects the meanings of words. Painting of the Tower of Babel by Pieter Bruegel the Elder, Kunsthistorisches Museum Wien, Vienna, Austria
What do we mean by the word beautiful? It depends not only on whom you ask, but in what language you ask them. According to a machine learning analysis of dozens of languages conducted at Princeton University, the meaning of words does not necessarily refer to an intrinsic, essential constant. Instead, it is significantly shaped by culture, history and geography. This finding held true even for some concepts that would seem to be universal, such as emotions, landscape features and body parts.
“Even for every day words that you would think mean the same thing to everybody, there’s all this variability out there,” said William Thompson, a postdoctoral researcher in computer science at Princeton University, and lead author of the findings, published in Nature Human Behavior Aug. 10. “We’ve provided the first data-driven evidence that the way we interpret the world through words is part of our culture inheritance.”
Language is the prism through which we conceptualize and understand the world, and linguists and anthropologists have long sought to untangle the complex forces that shape these critical communication systems. But studies attempting to address those questions can be difficult to conduct and time consuming, often involving long, careful interviews with bilingual speakers who evaluate the quality of translations. “It might take years and years to document a specific pair of languages and the differences between them,” Thompson said. “But machine learning models have recently emerged that allow us to ask these questions with a new level of precision.”
In their new paper, Thompson and his colleagues Seán Roberts of the University of Bristol, U.K., and Gary Lupyan of the University of Wisconsin, Madison, harnessed the power of those models to analyze over 1,000 words in 41 languages.
Instead of attempting to define the words, the large-scale method uses the concept of "semantic associations," or simply words that have a meaningful relationship to each other, which linguists find to be one of the best ways to go about defining a word and comparing it to another. Semantic associates of “beautiful,” for example, include “colorful,” “love,” “precious” and “delicate.”
The researchers built an algorithm that examined neural networks trained on various languages to compare millions of semantic associations. The algorithm translated the semantic associates of a particular word into another language, and then repeated the process the other way around. For example, the algorithm translated the semantic associates of "beautiful" into French and then translated the semantic associates of beau into English. The algorithm’s final similarity score for a word’s meaning came from quantifying how closely the semantics aligned in both directions of the translation.
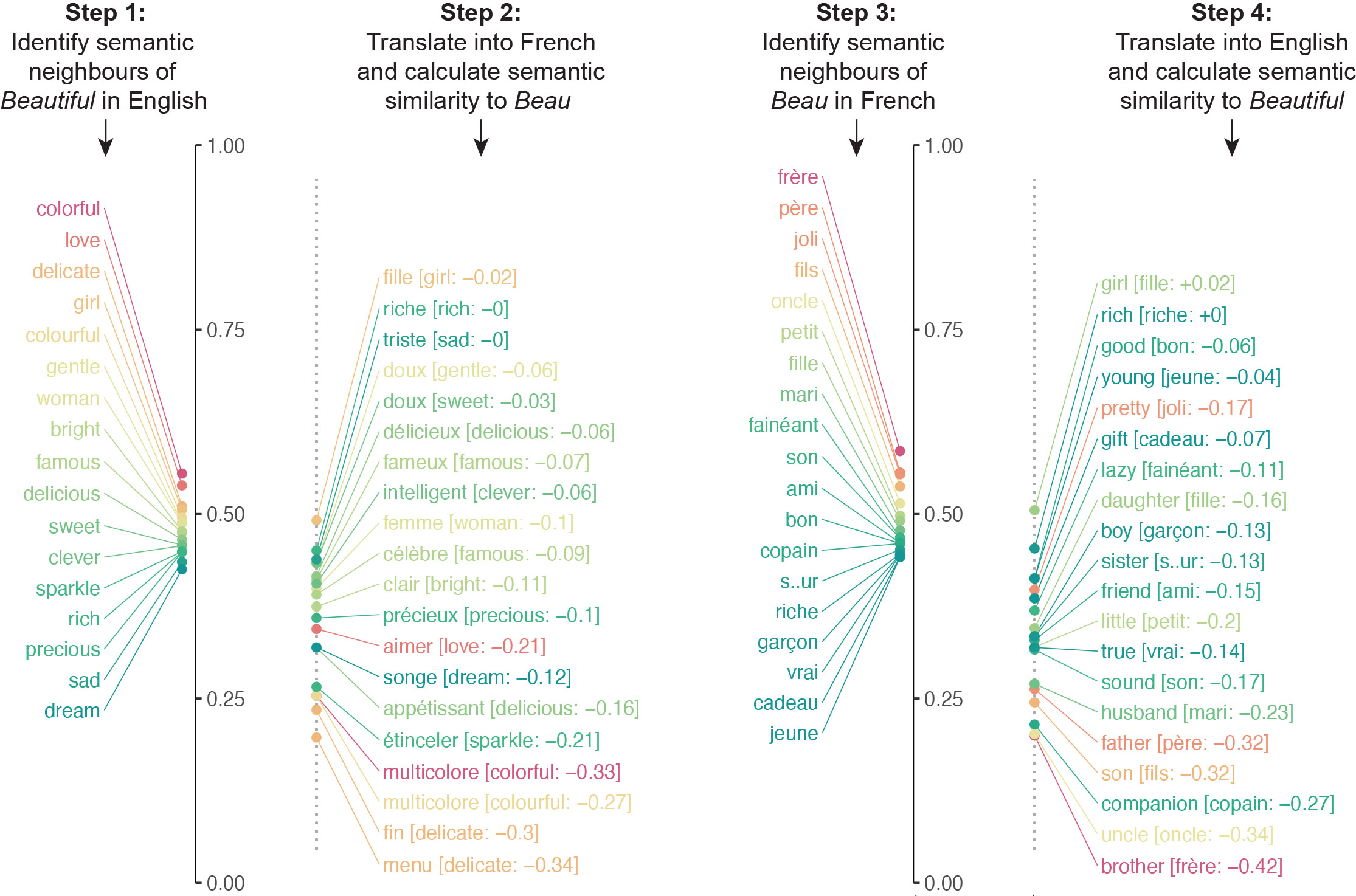
The algorithm translated the semantic associates of a particular word into another language, and then repeated the process the other way around. In this example, the semantic neighbors of "beautiful" were translated into French and then the semantic neighbors of "beau" were translated into English. The respective lists were substantially different because of different cultural associations. Image courtesy the researchers.
“One way to look at what we’ve done is a data-driven way of quantifying which words are most translatable,” Thompson said.
The findings revealed that there are some nearly universally-translatable words, primarily those that refer to numbers, professions, quantities, calendar dates and kinship. Many other word types, however, including those that referred to animals, food and emotions, were much less well matched in meaning.
In one final step, the researchers applied another algorithm that compared how similar the cultures that produced the two languages are, based on an anthropological dataset comparing things like marriage practices, legal systems and political organization of given language’s speakers.
The researchers found that their algorithm could correctly predict how easily two languages could be translated based on how similar the two cultures that speak them are. This shows that variability in word meaning is not just random. Culture plays a strong role in shaping languages—a hypothesis that theory has long predicted, but that researchers lacked quantitative data to support.
“This is an extremely nice paper that provides a principled quantification to issues that have been central to the study of lexical semantics,” said Damián Blasi, a language scientist at Harvard University, who was not involved in the new research. While the paper does not provide a definitive answer for all the forces that shape the differences in word meaning, the methods the authors established are sound, Blasi said, and the use of multiple, diverse data sources “is a positive change in a field that has systematically disregarded the role of culture in favor of mental or cognitive universals.”
Thompson agreed that he and his colleagues’ findings emphasize the value of “curating unlikely sets of data that are not normally seen in the same circumstances.” The machine learning algorithms he and his colleagues used were originally trained by computer scientists, while the datasets they fed into the models to analyze were created by 20th century anthropologists as well as more recent linguistic and psychological studies. As Thompson said, “Behind these fancy new methods, there’s a whole history of people in multiple fields collecting data that we’re bringing together and looking at in a whole new way.”
Thompson is a member of the Computational Cognitive Science Lab led by Tom Griffiths, the Henry R. Luce Professor of Information Technology, Consciousness, and Culture of Psychology and Computer Science. The lab is world leader in applying the methods of computer science to understanding human cognition, including using machine learning in novel ways to shed light on language and culture.