Clustering
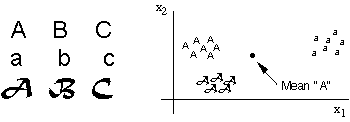
It frequently happens that the a given class is not homogeneous, but is
composed of a number of distinct subclasses. In the example shown above,
there are obviously three different kinds of letters in the "A"
class, and the average or mean feature vector may not represent any one
subclass, let alone all of them. In designing the classifier, it would make
sense to have three categories A1, A2 and A3,
and say that the input is an "A" if it matches either A1
or A2 or A3. In general, if we know that a class contains
k subclasses, we could design a two-stage classifier, in which we first
assign a feature vector x to a subclass, and then OR the
results to identify the class.
The problem of finding subclasses in a set of examples from a given class
is called unsupervised learning. The problem is easiest
when the feature vectors for examples in a subclass are close together and
form a cluster. We will consider four popular methods for
finding clusters:
 Back to Feature
Selection
Back to Feature
Selection  Up to Feature
Selection and Clustering
Up to Feature
Selection and Clustering