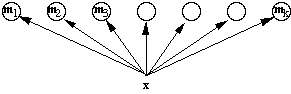
Let us arrange the units along a line as shown above. When an example
x is presented, Unit i responds according to some inverse
function of || x - mi ||, such
as exp( - || x - mi ||2
). The unit that responds most strongly has a "memory" mi
that is closest to x -- even though x
and mi might not be all that similar. We make
mi become more like x through
the updating rule
So far, this is the same as the sequential k-means
procedure. However, Kohonen makes two modifications. First, he says
that we should not update only mi, but that
we should also update other cluster centers that are in the neighborhood
of mi along the one-dimensional layout, i.e.,
units that are spatially near the unit having memory mi.
Second, he says that the size of the neighborhood should be programmed to
shrink as time goes on.
The result of Kohonen's modifications is that units that are spatially close
tend to develop similar memory vectors. Of course, the rate at which the
neighborhood shrinks is critical. If the neighborhood is large and it shrinks
very slowly, the cluster centers will tend to stick close to the overall
mean of all of the examples. At the other extreme, if the neighborhood shrinks
very rapidly, the results will be the same as one gets with the sequential
k-means procedure.
There is little theory to guide the choice of the shrinking schedule. However,
extensive experiments have shown that, with judicious trial and error, one
can often obtain useful clusterings that, in some sense, preserve topology.
See (Kohonen 1995) and (Ritter
et al. 1992) for many interesting examples.
![]() Back to Sequential
Back to Sequential
![]() Up to Clustering
Up to Clustering