Partnering
Partnering is permitted on this assignment. Before partnering, read the partnering section of the COS 226 collaboration policy. To submit the assignment while partnering with someone, make sure to create a group on TigerFile. Your group will attend the code review together, and your group should be the same as your group in K-d Trees, in particular, if you did it individually you should also do this one individually.
Learning objectives:
- Model a problem as a graph and apply graph search algorithms
Preamble
A quick reminder on the course policy. The autograder provides feedback only, it does not determine your grade. See the assignment FAQ for more details on the grading policy.
Our recommendation. Write your own code from scratch and aim to complete every requirement by the completion deadline. Treat each assignment as if the autograder score determined your grade. Working code that you understand is the sweet spot: it makes demos easy and reflects real learning. Start early to give yourself time to debug.
WordNet
WordNet is a semantic lexicon for the English language that computational linguists and cognitive scientists use extensively. For example, WordNet was a key component in IBM's Jeopardy-playing Watson computer system. WordNet groups words into sets of synonyms called synsets. For example, { AND circuit, AND gate } is a synset that represents a logical gate that fires only when all of its inputs fire. WordNet also describes semantic relationships between synsets. One such relationship is the is-a relationship, which connects a hyponym (more specific synset) to a hypernym (more general synset). For example, the synset { gate, logic gate } is a hypernym of { AND circuit, AND gate } because an AND gate is a kind of logic gate.
The WordNet digraph
Your first task is to build the WordNet digraph: each vertex v is an integer that represents a synset, and each directed edge v→w represents that w is a hypernym of v. The WordNet digraph is a rooted DAG: it is acyclic and has one vertex — the root — that is an ancestor of every other vertex. However, it is not necessarily a tree because a synset can have more than one hypernym. Here is a small subgraph of the WordNet digraph:
The WordNet input file formats
We now describe the two data files that you will use to create the WordNet digraph. The files are in comma-separated values (CSV) format: each line contains a sequence of fields, separated by commas.
-
List of synsets. The file
synsets.txtcontains all noun synsets in WordNet, one per line. Line i of the file (counting from 0) contains the information for synset i. The first field is the synset id, which is always the integer i; the second field is the synonym set (or synset); and the third field is its dictionary definition (or gloss), which is not relevant to this assignment (and so you can ignore it).
For example, line 36 means that the synset {
AND_circuit,AND_gate} has an id number of 36 and its gloss isa circuit in a computer that fires only when all of its inputs fire. The individual nouns that constitute a synset are separated by spaces. If a noun contains more than one word, the underscore character connects the words (and not the space character). Do not assume that the nouns within a synset appear in alphabetical order.A noun can appear in more than one synset, once for each of its distinct meanings, do not assume that the number of synsets in which a noun participates is bounded by a constant. Similarly, a synset can consist of exactly one noun, and multiple distinct synsets can contain the same single noun (each corresponding to a different meaning).
-
List of hypernyms. The file
hypernyms.txtcontains the hypernym relationships. Line i of the file (counting from 0) contains the hypernyms of synset i. The first field is the synset id, which is always the integer i; subsequent fields are the id numbers of the synset's hypernyms.
For example, line 36 means that synset 36 (
AND_circuit AND_gate) has 43273 (gate logic_gate) as its only hypernym. Line 34 means that synset 34 (AIDS acquired_immune_deficiency_syndrome) has two hypernyms: 48504 (immunodeficiency) and 49019 (infectious_disease).
Part 1: WordNet Data Type
Implement an immutable data type WordNet with the following API:
public class WordNet {
// constructor takes the name of the two input files
public WordNet(String synsets, String hypernyms)
// the set of all WordNet nouns
public Iterable<String> nouns()
// is the word a WordNet noun?
public boolean isNoun(String word)
// a synset (second field of synsets.txt) that is a shortest common ancestor
// of noun1 and noun2 (defined below)
public String sca(String noun1, String noun2)
// distance between noun1 and noun2 (defined below)
public int distance(String noun1, String noun2)
// unit testing
public static void main(String[] args)
}(Note that the implementations of distance() and sca() rely on data types described later.)
You may assume that the input files are in the specified format and that the underlying digraph is a rooted DAG.
WordNet Requirements
WordNet(String synsets, String hypernyms)
- Behavior: Construct the WordNet digraph from the two input files.
- Corner case: Throw
IllegalArgumentExceptionif any argument isnull. - Performance: Linearithmic (or better) in the input size. Assume the number of characters in a noun or synset is $O(1)$.
nouns()
- Behavior: Return the set of all WordNet nouns.
- Performance: Linear in the number of nouns.
isNoun(String word)
- Behavior: Return
trueifwordis a WordNet noun,falseotherwise. - Corner case: Throw
IllegalArgumentExceptionif the argument isnull. - Performance: Logarithmic (or better) in the number of nouns.
sca(String noun1, String noun2)
- Behavior: Return a synset (second field of
synsets.txt) that is a shortest common ancestor ofnoun1andnoun2. - Corner case: Throw
IllegalArgumentExceptionif either argument isnullor is not a WordNet noun. - Performance: Must make exactly one call to
ancestorSubset()inShortestCommonAncestor.
distance(String noun1, String noun2)
- Behavior: Return the distance between
noun1andnoun2. - Corner case: Throw
IllegalArgumentExceptionif either argument isnullor is not a WordNet noun. - Performance: Must make exactly one call to
lengthSubset()inShortestCommonAncestor.
Space: Linear in the input size (size of synsets and hypernyms files). Assume the number of characters in a noun or synset is $O(1)$.
Additional guidance
Read each input file only once, file I/O is expensive. Use the In library to read data one line at a time, the split() method in Java's String library to divide a line into fields, and Integer.parseInt() to convert string id numbers into int values. You can find an example using split() in Domain.java.
The root synset in the provided WordNet data is entity (synset id 38938).
Construct a single ShortestCommonAncestor object in the WordNet constructor and reuse it for all calls to sca() and distance().
Testing tips
Here are some interesting examples that you can use to test your code.
Nouns in multiple synsets. The noun President (capitalized) appears in two different synsets (ids 14479 and 14480).
Multiple paths to a common ancestor. The synset municipality has two paths to region: one through administrative_district → district and another through populated_area → geographic_area. The synsets individual and edible_fruit have several different paths to their common ancestor physical_entity.
Far-apart nouns. The following pairs of nouns have large distances:
| noun 1 | noun 2 | distance |
|---|---|---|
white_marlin |
mileage |
23 |
Black_Plague |
black_marlin |
33 |
American_water_spaniel |
histology |
27 |
Brown_Swiss |
barrel_roll |
29 |
Part 2: Shortest Common Ancestor
An ancestral path between two vertices v and w in a rooted DAG is a directed path from v to a common ancestor x, together with a directed path from w to the same ancestor x. A shortest ancestral path is an ancestral path of minimum total length. We refer to the common ancestor in a shortest ancestral path as a shortest common ancestor. Note that a vertex is considered an ancestor of itself. A shortest common ancestor always exists because the root is an ancestor of every vertex. Note also that an ancestral path is a path, but not a directed path.
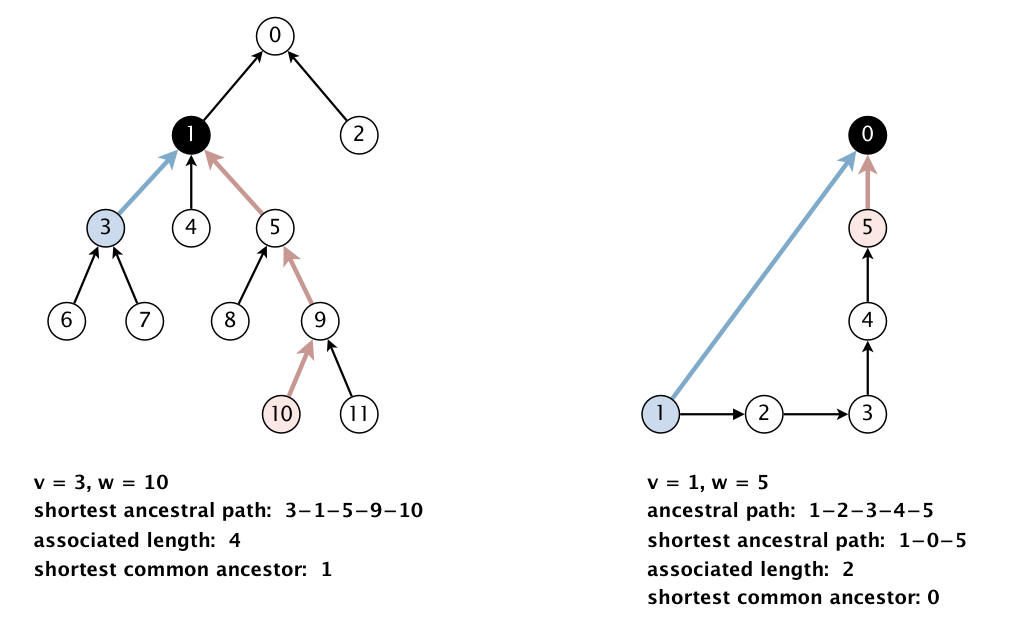
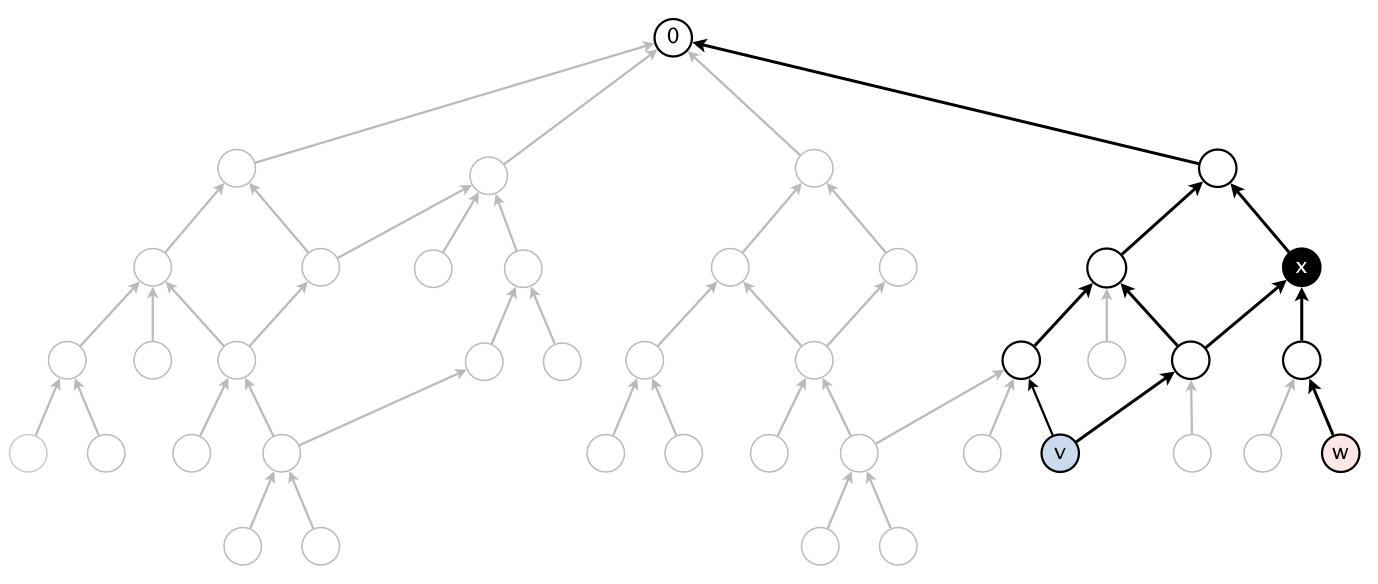
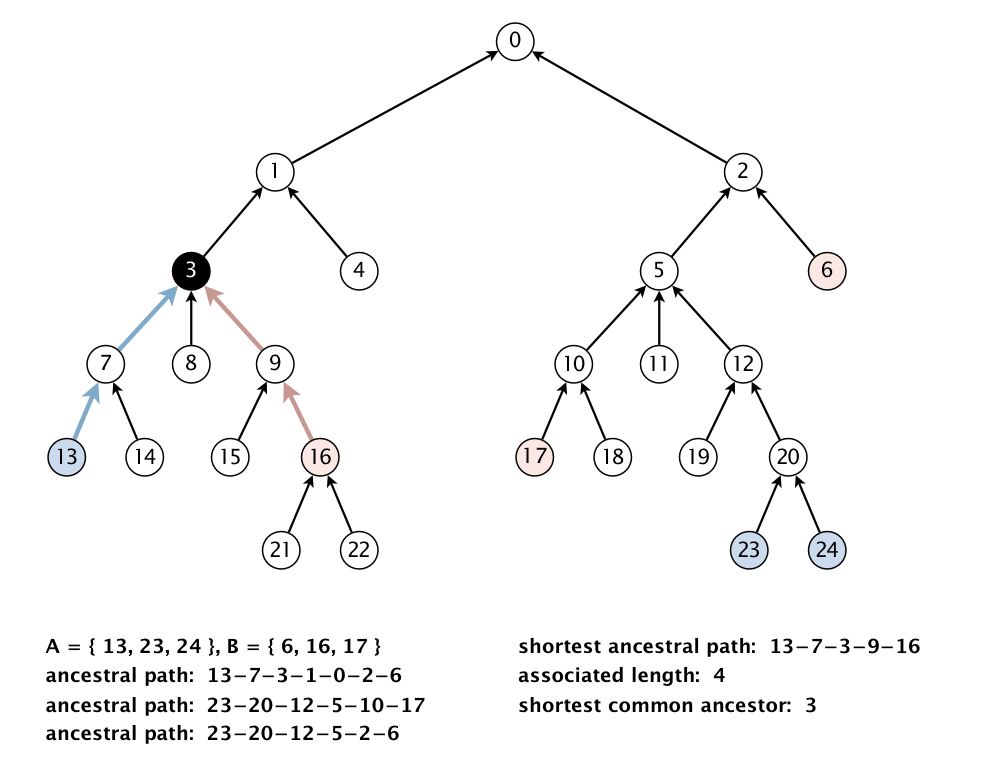
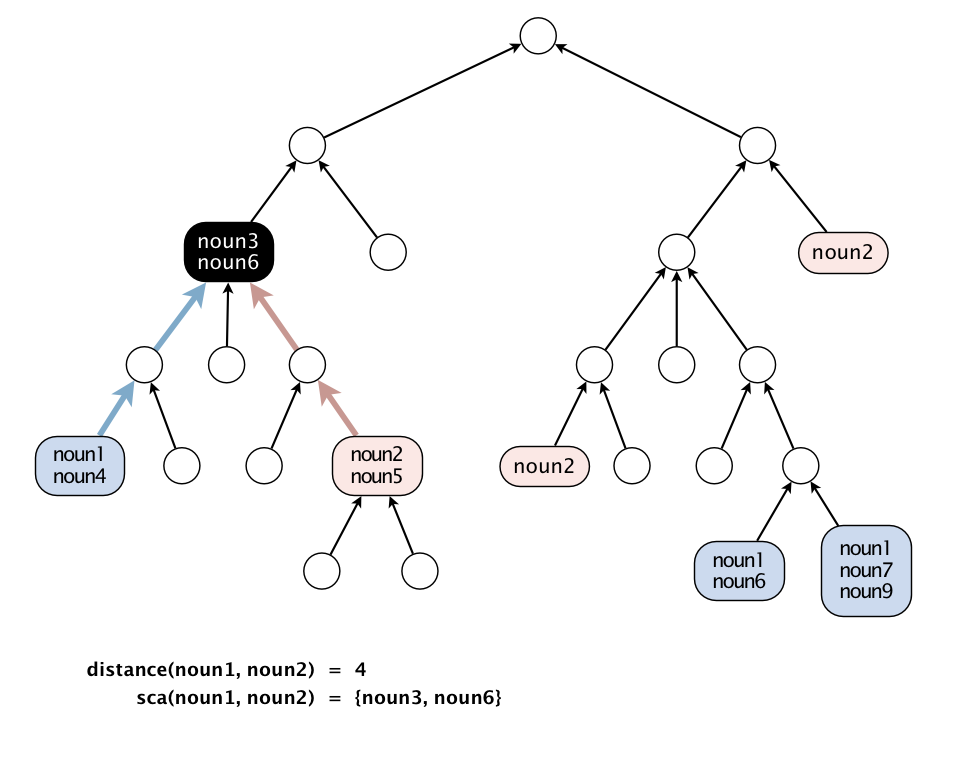
We generalize the notion of shortest common ancestor to subsets of vertices. A shortest ancestral path of two subsets of vertices A and B is a shortest ancestral path among all pairs of vertices v and w, with v in A and w in B. As an example, the following figure (digraph25.txt) identifies several (but not all) ancestral paths between the red and blue vertices, including the shortest one.
Implement an immutable data type ShortestCommonAncestor with the following API. You must use Digraph from algs4.jar, do not implement your own digraph.
public class ShortestCommonAncestor {
// constructor takes a rooted DAG as argument
public ShortestCommonAncestor(Digraph G)
// length of shortest ancestral path between v and w
public int length(int v, int w)
// a shortest common ancestor of vertices v and w
public int ancestor(int v, int w)
// length of shortest ancestral path of vertex subsets A and B
public int lengthSubset(Iterable<Integer> subsetA, Iterable<Integer> subsetB)
// a shortest common ancestor of vertex subsets A and B
public int ancestorSubset(Iterable<Integer> subsetA, Iterable<Integer> subsetB)
// test client (see below)
public static void main(String[] args)
}ShortestCommonAncestor Requirements
ShortestCommonAncestor(Digraph G)
- Behavior: Construct a
ShortestCommonAncestorfrom a rooted DAG. - Corner case: Throw
IllegalArgumentExceptionif the argument is not a rooted DAG. - Performance: $O(E + V)$ time and space.
length(int v, int w)
- Behavior: Return the length of a shortest ancestral path between
vandw. - Corner case: Throw
IllegalArgumentExceptionif any vertex is outside its prescribed range. - Performance: $O(E + V)$ time.
ancestor(int v, int w)
- Behavior: Return a shortest common ancestor of vertices
vandw. - Corner case: Throw
IllegalArgumentExceptionif any vertex is outside its prescribed range. - Performance: $O(E + V)$ time.
lengthSubset(Iterable<Integer> subsetA, Iterable<Integer> subsetB)
- Behavior: Return the length of a shortest ancestral path of vertex subsets
AandB. - Corner case: Throw
IllegalArgumentExceptionif any argument isnull, any iterable contains zero vertices, any iterable contains anullitem, or any vertex is outside its prescribed range. - Performance: $O(E + V)$ time.
ancestorSubset(Iterable<Integer> subsetA, Iterable<Integer> subsetB)
- Behavior: Return a shortest common ancestor of vertex subsets
AandB. - Corner case: Throw
IllegalArgumentExceptionif any argument isnull, any iterable contains zero vertices, any iterable contains anullitem, or any vertex is outside its prescribed range. - Performance: $O(E + V)$ time.
Space: $O(E + V)$.
Additional guidance
Since Digraph is mutable, the constructor should make a defensive copy of the argument (e.g., by calling the copy constructor in Digraph) to preserve immutability.
To achieve $O(E + V)$ time for lengthSubset() and ancestorSubset(), use a multi-source version of breadth-first search, which initializes BFS from all source vertices simultaneously rather than from a single source. The BreadthFirstDirectedPaths class in algs4.jar provides exactly this functionality — its constructor accepts an iterable of sources. We recommend using this class rather than implementing your own BFS. A naive approach that runs BFS separately for each pair of vertices in the two subsets will be too slow.
To validate that the input digraph is a rooted DAG, break the check into two parts: (1) verify that the digraph is acyclic, and (2) verify that the DAG has a single root. You can use DirectedCycle or Topological from algs4.jar for cycle detection.
Testing tips
The following test client takes the name of a digraph input file as a command-line argument, reads vertex pairs from standard input, and prints the length and ancestor for each pair:
public static void main(String[] args) {
In in = new In(args[0]);
Digraph G = new Digraph(in);
ShortestCommonAncestor sca = new ShortestCommonAncestor(G);
while (!StdIn.isEmpty()) {
int v = StdIn.readInt();
int w = StdIn.readInt();
int length = sca.length(v, w);
int ancestor = sca.ancestor(v, w);
StdOut.printf("length = %d, ancestor = %d\n", length, ancestor);
}
}~/Desktop/wordnet> java-algs4 ShortestCommonAncestor digraph1.txt
3 10
length = 4, ancestor = 1
8 11
length = 3, ancestor = 5
6 2
length = 4, ancestor = 0In addition to the provided digraph*.txt files, design small rooted DAGs to test and debug your code.
Part 3: Outcast Detection
Semantic relatedness refers to the degree to which two concepts are related. Measuring semantic relatedness is a challenging problem. For example, you consider George W. Bush and John F. Kennedy (two U.S. presidents) to be more closely related than George W. Bush and chimpanzee (two primates). It might not be clear whether George W. Bush and Eric Arthur Blair are more related than two arbitrary people. However, both George W. Bush and Eric Arthur Blair (a.k.a. George Orwell) are famous communicators and, therefore, closely related.
We define the semantic relatedness of two WordNet nouns x and y as follows:
- A = set of synsets in which x appears
- B = set of synsets in which y appears
- distance(x, y) = length of shortest ancestral path of subsets A and B
- sca(x, y) = a shortest common ancestor of subsets A and B
This is the notion of distance that you will use to implement the distance() and sca() methods in the WordNet data type.
Outcast data type
Given a list of WordNet nouns $x_1, x_2, \ldots, x_n$, which noun is the least related to the others? To identify an outcast, compute the sum of the distances between each noun and every other one:
$$d_i = \text{distance}(x_i, x_1) + \text{distance}(x_i, x_2) + \cdots + \text{distance}(x_i, x_n)$$
and return a noun $x_t$ for which $d_t$ is maximum. Note that $\text{distance}(x_i, x_i) = 0$, so it will not contribute to the sum.
Implement an immutable data type Outcast with the following API:
public class Outcast {
// constructor takes a WordNet object
public Outcast(WordNet wordnet)
// given an array of WordNet nouns, return an outcast
public String outcast(String[] nouns)
// test client (see below)
public static void main(String[] args)
}Outcast Requirements
Outcast(WordNet wordnet)
- Behavior: Construct an
Outcastobject from aWordNetobject.
outcast(String[] nouns)
- Behavior: Given an array of WordNet nouns, return an outcast.
- Assumption: The argument contains only valid WordNet nouns and at least two such nouns.
- Performance: At most a quadratic number of calls to
distance()inWordNet.
Testing tips
The following test client takes the name of a synset file, a hypernym file, and one or more outcast files as command-line arguments, and prints an outcast in each file:
public static void main(String[] args) {
WordNet wordnet = new WordNet(args[0], args[1]);
Outcast outcast = new Outcast(wordnet);
for (int t = 2; t < args.length; t++) {
In in = new In(args[t]);
String[] nouns = in.readAllStrings();
StdOut.println(args[t] + ": " + outcast.outcast(nouns));
}
}~/Desktop/wordnet> java-algs4 Outcast synsets.txt hypernyms.txt outcast5.txt outcast8.txt outcast11.txt
outcast5.txt: table
outcast8.txt: bed
outcast11.txt: potatoDeliverables
Project files
The file wordnet.zip contains sample data files and test clients. It also contains feedback.txt, which you should fill out, and acknowledgments.txt, which you should complete with citations and collaboration information.
Submission
Submit WordNet.java, ShortestCommonAncestor.java, and Outcast.java. Also submit any other supporting files (excluding those in algs4.jar).
Do not call any library functions other than those in
java.lang,
java.util,
and algs4.jar.
Finally, submit feedback.txt and acknowledgments.txt files and answer the questions.
| File | Purpose |
|---|---|
WordNet.java |
WordNet data type with semantic distance and SCA queries. |
ShortestCommonAncestor.java |
Shortest common ancestor in a rooted DAG. |
Outcast.java |
Outcast detection using semantic distance. |
feedback.txt |
Answers the assignment feedback questions. |
acknowledgments.txt |
Lists collaborators and external resources used. |
Advice and Further Challenges
Suggested Approach
To help you work through the assignment, here is a suggested list of steps for how you might make progress. You don't have to follow this list to complete the assignment and in fact we recommend you don't look at it unless you get stuck.
List of steps.
-
Download the project files. Download
wordnet.zip. It contains sample input files forShortestCommonAncestor,WordNet, andOutcast. -
Implement
ShortestCommonAncestor. First, think carefully about designing a correct and efficient algorithm for computing the shortest common ancestor. Consult a staff member if you're unsure. In addition to the provideddigraph*.txtfiles, design small rooted DAGs to test and debug your code. Modularize by sharing common code amonglength(),ancestor(),lengthSubset(), andancestorSubset(). -
Validate the input digraph. Add code to the
ShortestCommonAncestorconstructor to detect whether a digraph is a rooted DAG. A digraph is a rooted DAG if it is acyclic and has one vertex — the root — that is an ancestor of every other vertex. -
Read and parse the input files. Read
synsets.txtandhypernyms.txtinside theWordNetconstructor. Don't worry about storing the data in any data structures yet. Test that you are parsing the input correctly before proceeding. -
Build the
WordNetdata structures. Divide the constructor into two (or more) private methods:- Read the synsets file and build appropriate data structures. Record the number of synsets for use when constructing the underlying digraph from the hypernyms file.
- Read the hypernyms file and build a
Digraph.
-
Implement the remaining
WordNetmethods. Use yourShortestCommonAncestorto implementsca()anddistance(). -
Implement
Outcast. This should be relatively straightforward by calling the appropriate methods from theWordNetdata type.
Leaderboard
The leaderboard is an optional, ungraded challenge where you can compare the performance of your ShortestCommonAncestor implementation against other students. Submit your solution to the separate leaderboard TigerFile instance for a friendly competition — you choose a nickname when submitting, so your identity can remain anonymous.
Further Challenges
Sublinear SCA
Modify your ShortestCommonAncestor implementation so that the methods length(), lengthSubset(), ancestor(), and ancestorSubset() take time proportional to the number of vertices and edges reachable from the argument vertices (or better), rather than $O(E + V)$. For example, to compute the shortest common ancestor of v and w in the following digraph, your algorithm can examine only the highlighted vertices and edges; it cannot initialize any vertex-indexed arrays.