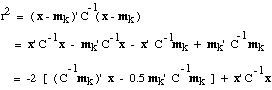
This should remind you of the similar expression we obtained for a minimum-Euclidean-distance
classifier. Once again we can obtain linear discriminant functions by
maximizing the expression in the brackets. This time we define the linear
discriminant function g(xk) by
where
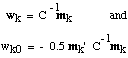
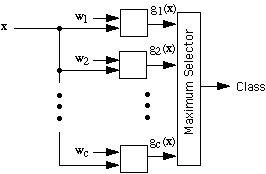
This result is very useful. Although it gives up the advantages of having
curved decision boundaries, it retains the advantages of being invariant
to linear transformations. In addition, it reduces the memory requirements
from the c d-by-d covariance matrices to the c d-by 1 weight vectors w1,
w2, ... , wc, with
a corresponding speed-up in the computation of the discriminant functions.
Finally, when the covariance matrices are the same for all c classes, one
can pool the data from all the classes and get a much better results from
a limited amount of data.
![]() Back to Metric
Back to Metric ![]() Up to Mahalanobis
Up to Mahalanobis