Partnering
Partnering is permitted on this assignment. Before partnering, read the partnering section of the COS 226 collaboration policy. To submit the assignment while partnering with someone, make sure to create a group on TigerFile. Your group will attend the code review together, and your group should be the same as your group in WordNet, in particular, if you did it individually you should also do this one individually.
Learning objectives:
- Apply multiple algorithms to build a machine learning pipeline
- Implement a simplified version of the AdaBoost algorithm
In this assignment you will implement a few algorithms which, when put together, form a machine learning model to detect fraudulent credit card transactions. The model is a simplified version of one that could be employed in the real world.
Preamble
A quick reminder on the course policy. The autograder provides feedback only, it does not determine your grade. See the assignment FAQ for more details on the grading policy.
Our recommendation. Write your own code from scratch and aim to complete every requirement by the completion deadline. Treat each assignment as if the autograder score determined your grade. Working code that you understand is the sweet spot: it makes demos easy and reflects real learning. Start early to give yourself time to debug.
The fraud detection problem
Consider a set of $m$ points in 2D space, each representing coordinates of retail establishments (shops, restaurants, etc.) on a map. These points are represented using the immutable data type Point2D from algs4.jar. You may find the distanceTo() and distanceSquaredTo() methods useful for computing Euclidean distances. Below is an example of locations in a map of Princeton.
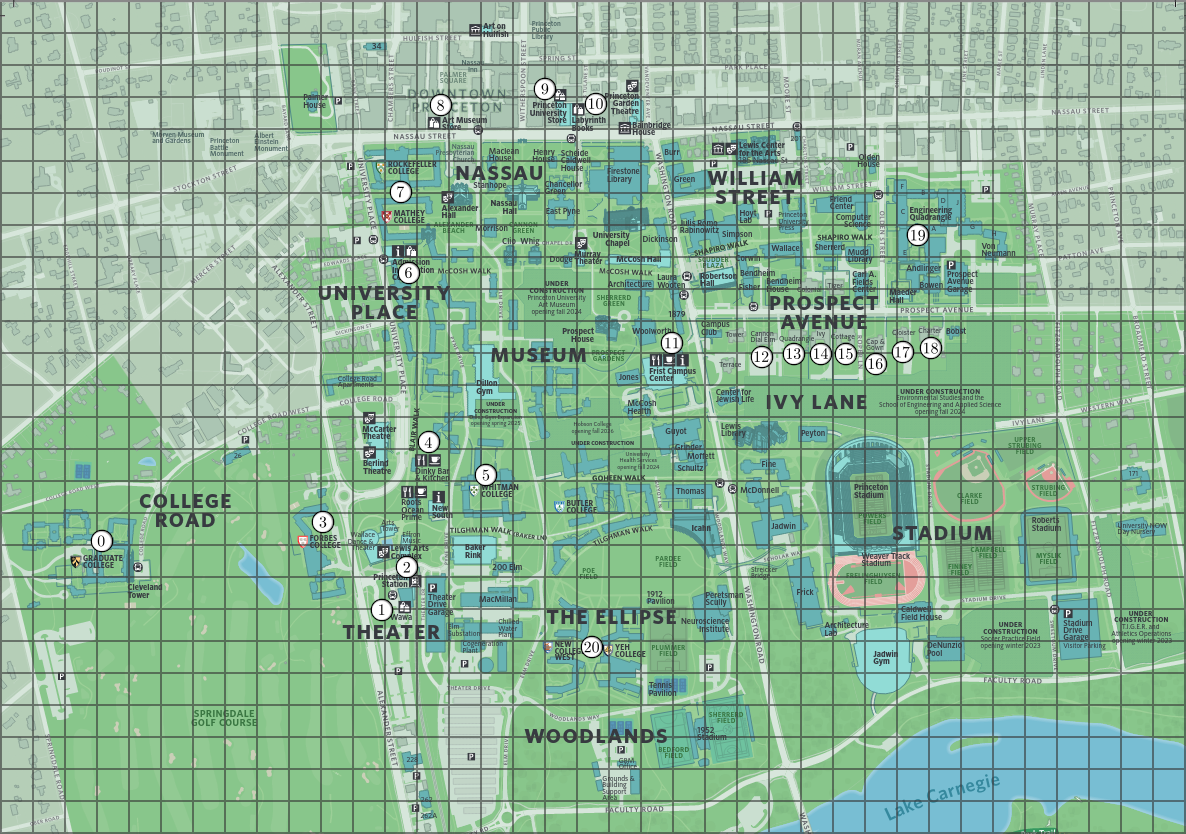
Additionally, you are given a data set with $n \ge 1$ labeled transaction summaries. A transaction summary is an array of $m$ non-negative integers, one per location, representing the amount of money spent at each location by a particular person. A label is either clean or fraud, indicating whether a fraudulent transaction was detected in the corresponding transaction summary. Here is an example: each number corresponds to a location in the map (e.g., the first number represents the amount of money spent at "Graduate College," the leftmost point).
| 5 | 6 | 7 | 0 | 6 | 7 | 5 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | clean |
The intuition is that fraudulent spending tends to look different from a person's normal patterns — for example, a burst of purchases at unusual locations. Nearby locations also tend to behave similarly, so grouping them into clusters produces a more robust signal than treating each one independently (which motivates Part 1).
You will create a simple machine learning model that learns from a data set: given a collection of labeled transaction summaries (the training set), the model extracts patterns that distinguish clean from fraud, then uses those patterns to label new, unseen transaction summaries. These labels are represented by integers: 0 for clean and 1 for fraud.
Part 1: Dimensionality Reduction
Before feeding the data into the machine learning model, you will first reduce the dimension of the input (the transaction summaries) using a clustering algorithm. This algorithm receives $m$ locations as Point2D objects, as well as a number $k$ (between 1 and $m$) of clusters. The goal is to output a partition of the points into $k$ clusters (groups) such that the points in the same cluster are close together in Euclidean distance.
This step not only makes the model more efficient (since we can now work with arrays of length $k$ instead of $m$), but it also improves its accuracy: grouping nearby locations aggregates spending data in a meaningful way, which helps mitigate overfitting.
The clustering algorithm proceeds as follows:
- Create a complete edge-weighted graph (using
EdgeWeightedGraph) with $m$ vertices (one per location) and an edge connecting each pair of locations, whose weight is the Euclidean distance between the two points. The vertices, numbered from $0$ to $m - 1$, must correspond to the sequence of locations in the input. - Compute the minimum spanning tree of the graph.
- Consider only the $m - k$ lowest-weight edges of the spanning tree and form a new graph (the cluster graph) with them.
- Each cluster is now given by a connected component in this graph (note that the cluster graph has exactly $k$ connected components).
You don't have to implement all these steps from scratch; there are several helpful classes in algs4.jar that you can use (see the implementation requirements below).
The following images show the minimum spanning tree and the clusters obtained from the Princeton locations above, with $k = 5$. In the image to the right, clusters are indicated by colors and dashed lines represent the MST edges excluded from the cluster graph.
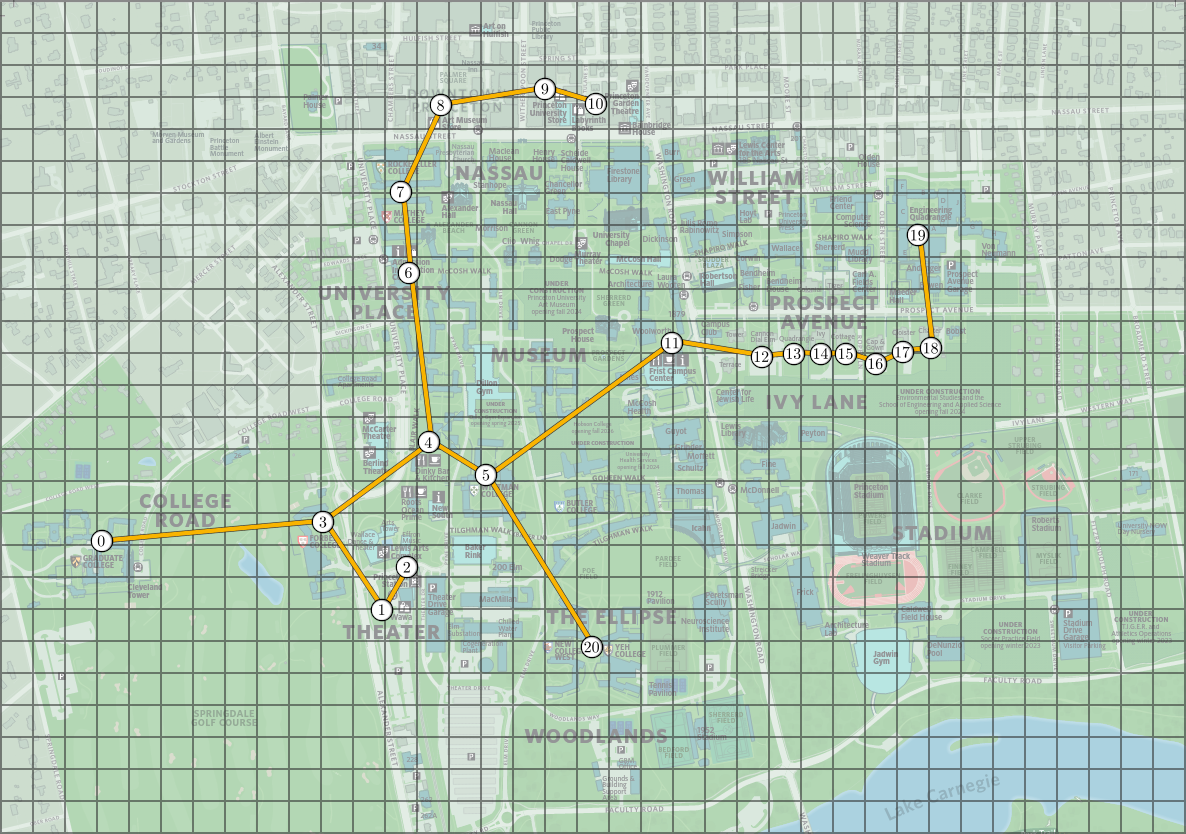
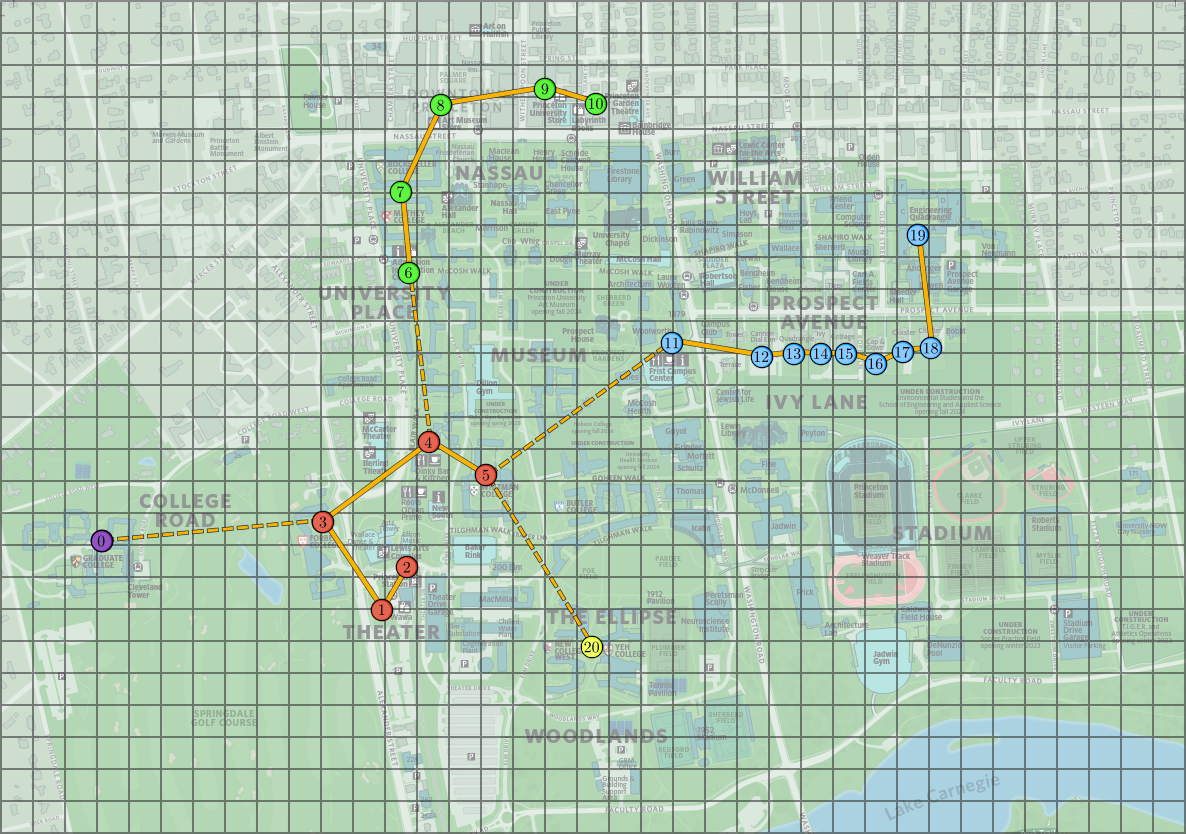
We can now reduce the dimension of each transaction summary by summing all entries corresponding to the same cluster, yielding a new array with $k$ elements (reduced from $m$). This is illustrated below, where each color labels a cluster in the image above.
| 5 | 6 | 7 | 0 | 6 | 7 | 5 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | Original |
| 5 | 26 | 24 | 39 | 7 | Reduced |
To help you test your code, we provide the file princeton_locations.txt, formatted as follows: the first line contains the number $m$ of locations, followed by $m$ lines with the $(x, y)$ coordinates of each location. The order of the points matches the above images (e.g., the first point represents the "Graduate College"). We also include princeton_locations_mst.txt, which contains the edges of the Euclidean graph's minimum spanning tree.
The Clustering data type
Implement an immutable data type Clustering with the following API:
public class Clustering {
// run the clustering algorithm and create the clusters
public Clustering(Point2D[] locations, int k)
// return the cluster of the ith location
public int clusterOf(int i)
// use the clusters to reduce the dimensions of an input
public int[] reduceDimensions(int[] input)
// unit testing (optional)
public static void main(String[] args)
}Note that clusterOf() must return an integer between $0$ and $k - 1$ satisfying the following condition: clusterOf(i) and clusterOf(j) are equal if and only if the $i$th and $j$th points belong to the same cluster.
Clustering Requirements
Clustering(Point2D[] locations, int k)
- Behavior: Run the clustering algorithm on the given locations and create $k$ clusters.
- Corner case: Throw
IllegalArgumentExceptionif any argument isnullor $k$ is not in the range $[1, m]$. - Implementation: Use
KruskalMSTandCCfromalgs4.jarto compute the MST and connected components. - Performance: $O(m^2 \log m)$ time.
clusterOf(int i)
- Behavior: Return the cluster of the $i$th location.
- Corner case: Throw
IllegalArgumentExceptionif $i$ is not in the range $[0, m - 1]$. - Performance: Constant time.
reduceDimensions(int[] input)
- Behavior: Use the clusters to reduce the dimensions of the given input array from $m$ to $k$.
- Corner case: Throw
IllegalArgumentExceptionif the argument isnullor has length different from $m$. - Performance: $O(m)$ time.
Part 2: Weak Learners
A weak learner is a machine learning model that performs marginally better than a random decision — in this context, predicting the correct label slightly more than $50\%$ of the time. You will implement a model known as a decision stump, a popular choice for weak learners.
Your decision stump takes as input a sequence of $n$ dimension-reduced transaction summaries, each an array of $k$ integers. In other words, the input is an $n$-by-$k$ array of integers input[][], where input[i][j] is the amount of money the reduced transaction summary i spent at cluster j. Each input is labeled with an integer, either 0 or 1 (corresponding to clean or fraud), given in an integer array labels[] of length $n$. Each input is also associated with a non-negative weight, given by the double[] array weights[] of length $n$ (which will be used in the boosting part of this assignment). Note that WeakLearner itself does not depend on Clustering: it works on any $n$-by-$k$ integer array, regardless of how it was produced.
From the input data and labels, the decision stump "learns" a predictor: a function that takes a single sample (a new transaction summary as an array of $k$ integers) and outputs a binary prediction, 0 or 1.
Note: the following description might seem a bit overwhelming at first. Try to read all of it, then study the examples in the images; the visual representations are very helpful.
Since each input is an array of length $k$, we can think of them as points in $k$-dimensional space (the $x$-coordinate corresponds to index 0, the $y$-coordinate to index 1, and so on). A decision stump classifies a point based on only a single coordinate. For example, $x \leq 4$ is a decision stump that labels all points with $x$-coordinate at most $4$ as 0 and all other points as 1. Geometrically, a decision stump corresponds to a hyperplane perpendicular to one of the axes: all points on one side are labeled 0 and points on the other side are labeled 1.
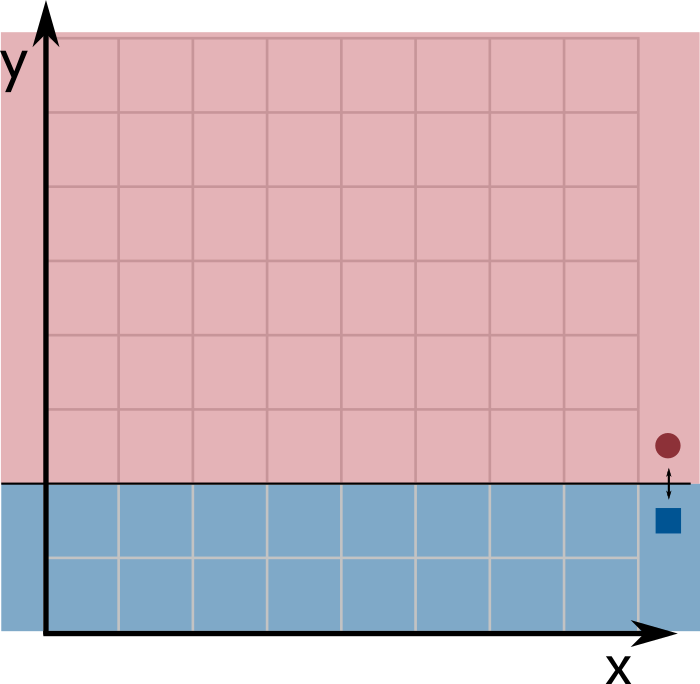
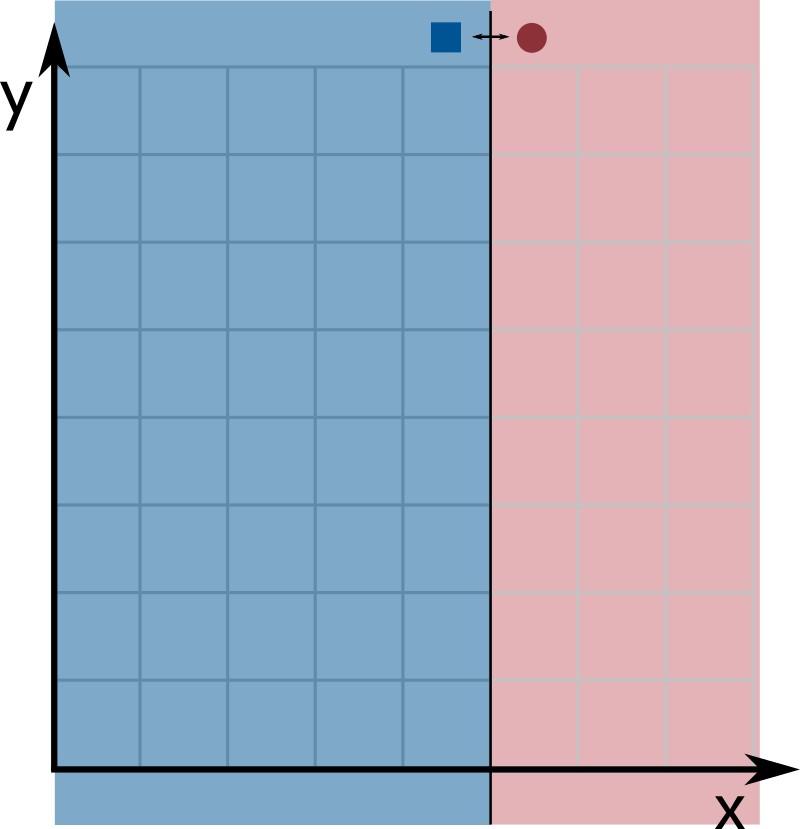
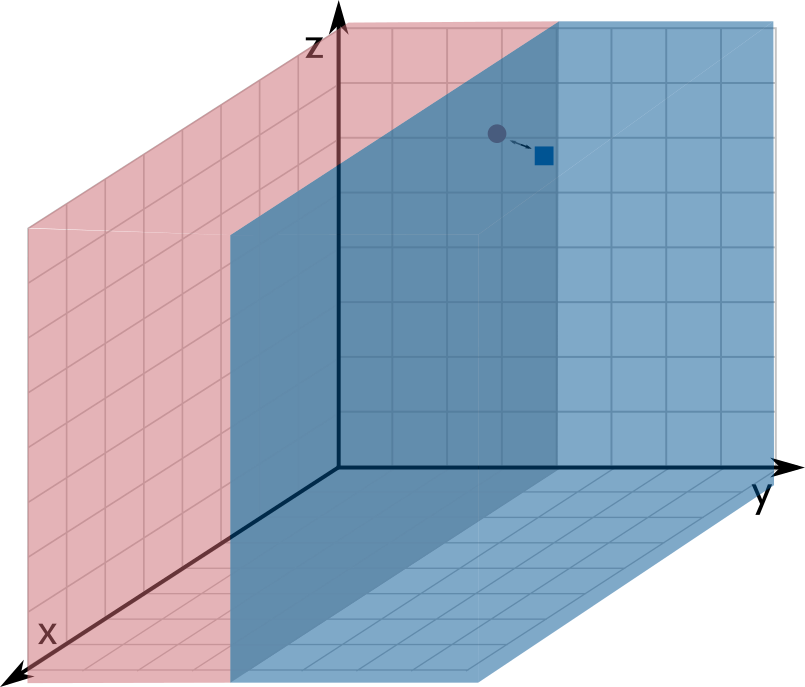
We use three integers to describe a decision stump: a dimension predictor $d_p$ (an integer between $0$ and $k - 1$, selecting the coordinate to partition), a value predictor $v_p$ (a non-negative integer, where the partition occurs), and a sign predictor $s_p$ (either $0$ or $1$, choosing which side of the partition gets which label). Formally, a decision stump with these parameters labels a $k$-dimensional input point $\textsf{sample}$ as follows:
- If $s_p = 0$: predict
0if $\textsf{sample}[d_p] \leq v_p$, and1otherwise. - If $s_p = 1$: predict
1if $\textsf{sample}[d_p] \leq v_p$, and0otherwise.
The images below show an example with $n = 8$ inputs of dimension $k = 2$, where dimensions 0 and 1 correspond to the $x$- and $y$-axes. Blue squares are label 0 and red circles are label 1. The line splits dimension $d_p = 1$ at coordinate $v_p = 4$: since $s_p = 1$, points above the line ($y$-coordinate larger than $4$) are labeled 0, and points at or below the line ($y$-coordinate at most $4$) are labeled 1.
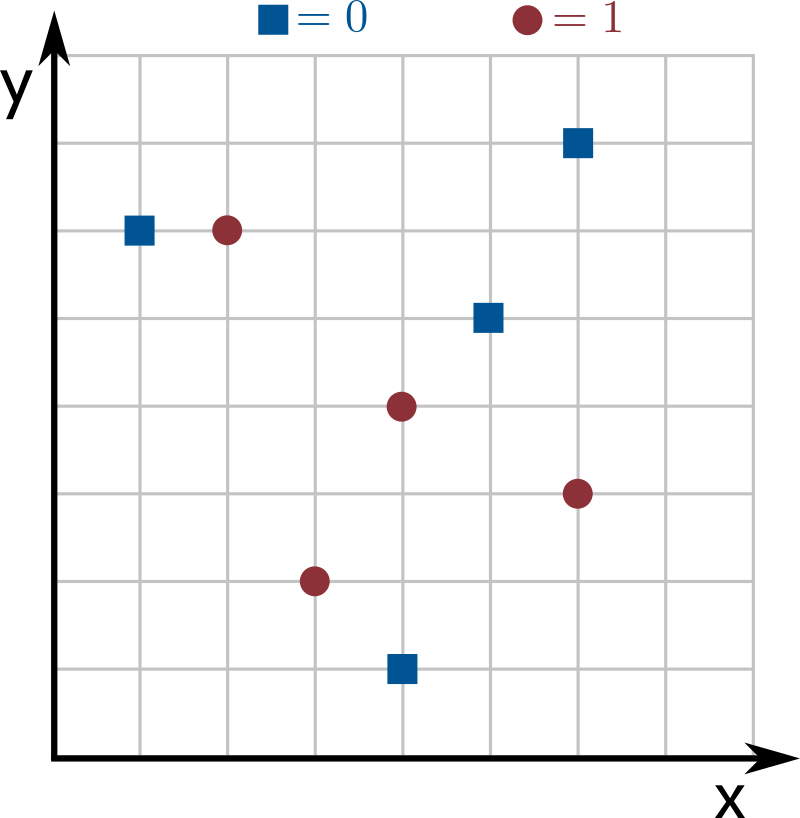
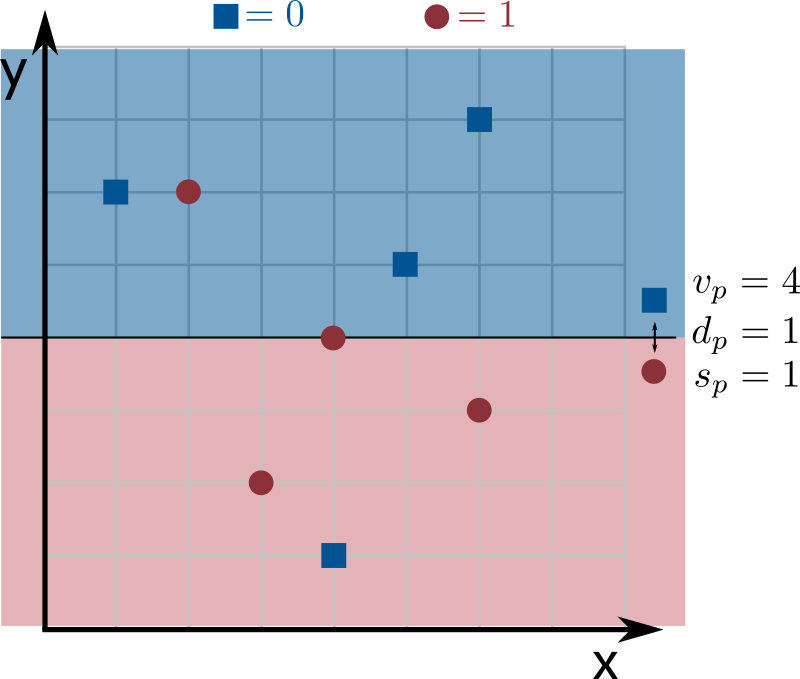
Your goal is to find the decision stump that best represents the input data (this step is called training the model). That is, find the values of $d_p$, $v_p$, and $s_p$ that maximize the total weight of correctly classified inputs (the sum of the weights of inputs whose predicted label matches the value in labels[]).
If all points have weight $1$ in the example above, the weight of correctly classified inputs is $6$ (all points are correct except for one blue square and one red circle). Since no other decision stump mislabels fewer than 2 points, this is the optimal stump.
The WeakLearner data type
Implement an immutable data type WeakLearner with the following API:
public class WeakLearner {
// train the weak learner
public WeakLearner(int[][] input, double[] weights, int[] labels)
// return the prediction of the learner for a new sample
public int predict(int[] sample)
// return the dimension the learner uses to separate the data
public int dimensionPredictor()
// return the value the learner uses to separate the data
public int valuePredictor()
// return the sign the learner uses to separate the data
public int signPredictor()
// unit testing
public static void main(String[] args)
}WeakLearner Requirements
WeakLearner(int[][] input, double[] weights, int[] labels)
- Behavior: Train the weak learner by finding the optimal decision stump for the given input, weights, and labels.
- Corner case: Throw
IllegalArgumentExceptionif any argument isnull, the lengths ofinput[][],weights[], andlabels[]are incompatible, the length ofinput[][]is zero or any element has zero length, the values ofweights[]are not all non-negative, or the values oflabels[]are not all either0or1. - Performance: $O(kn \log n)$ time.
predict(int[] sample)
- Behavior: Return the prediction (
0or1) for the given sample. - Corner case: Throw
IllegalArgumentExceptionif the argument isnullor has incompatible length. - Performance: Constant time.
dimensionPredictor(), valuePredictor(), signPredictor()
- Behavior: Return the dimension, value, or sign predictor, respectively.
- Performance: Constant time.
Additional guidance
When there are multiple decision stumps that achieve the same maximum weight of correctly classified inputs, you may break ties in any way you like.
Implementing the constructor is probably the trickiest part of the assignment. A good starting strategy is to first get a simpler $O(kn^2)$ solution working: try all possible values of $d_p$ (there are $k$), all possible values of $s_p$ (there are $2$), and all values of $v_p$, computing the weight of correct predictions for each combination by looping through all $n$ input points.
But can't $v_p$ be any possible non-negative integer? Yes, but notice that you only need to consider values that are actual coordinates in the input (there are $n$ of them) — a decision stump with $v_p$ between two consecutive input coordinates makes the same predictions, so its weight of correct predictions is identical. For example, in the grid image above, moving the prediction line up by less than $1$ (setting $v_p$ to anything from $4$ to just under $5$) produces the same classifications.
Once you have this working, think about how to avoid repeatedly iterating through all points for every possible decision stump by finding a more clever way to compute the weight of correct predictions. Hint: if you sorted the points by a certain coordinate, could you find the best decision stump for that coordinate in $\Theta(n)$ time?
One particularly tricky case is when there are points with duplicate coordinates (i.e., there exists some coordinate j and two distinct points i1 and i2 for which input[i1][j] == input[i2][j]). It is easier to first ignore this case and get a solution that works when all coordinates are distinct. The tests on TigerFile are divided into inputs with and without duplicate coordinates to help you with debugging.
Testing tips
The project folder includes small test cases in the stump_i.txt files, designed to find corner-case bugs in your WeakLearner code. For each one, the corresponding stump_i.ans.txt contains the parameters of the best decision stump for that data set.
All the examples are based on the point sets in the following images (the middle one has no duplicate coordinates, but the other two do):
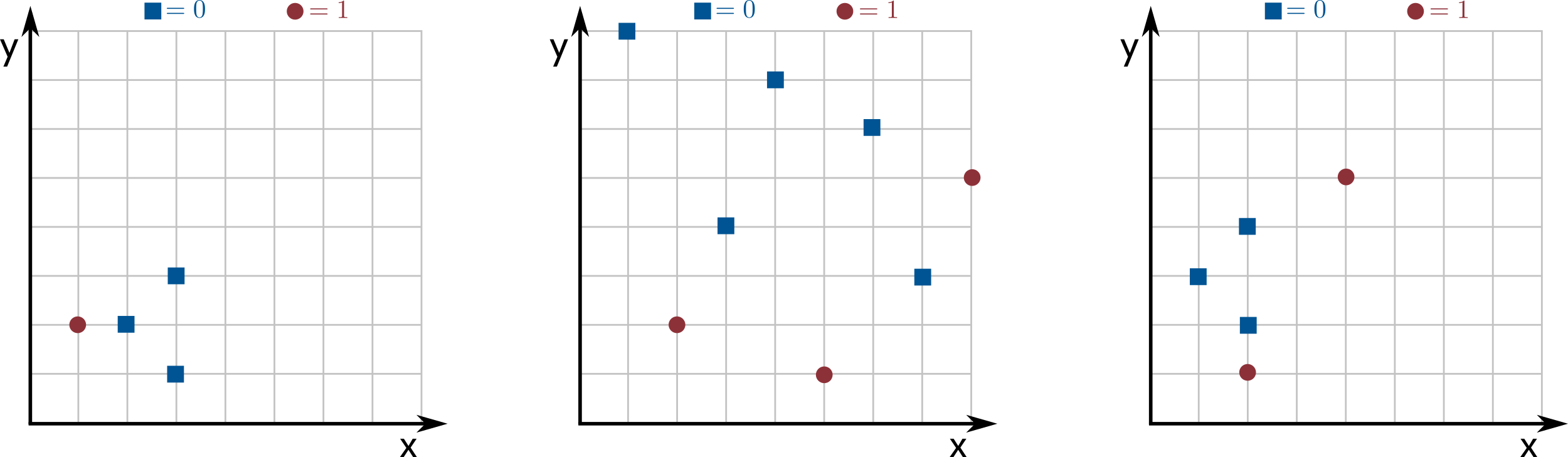
Description of each test case.
stump_1.txt— the left image with all weights equal to $1$.stump_2.txt— the center image with all weights equal to $0.125$.stump_3.txt— the center image with all weights equal to $0.01$ except for the topmost red circles, which have weight $0.47$.stump_4.txt— the right image with all weights equal to $1$ except for the lowest red circle, which has weight $2$.stump_5.txt— identical tostump_4.txt, but all labels are flipped.
The first example tests basic logic. The next two verify that weights are handled correctly. The last two help debug a common bug in efficient solutions: forgetting that multiple points can share the same coordinate.
To check your results, use the WeakLearnerVisualizer.java client provided in the project folder:
~/Desktop/fraud> java-algs4 WeakLearnerVisualizer stump_1.txt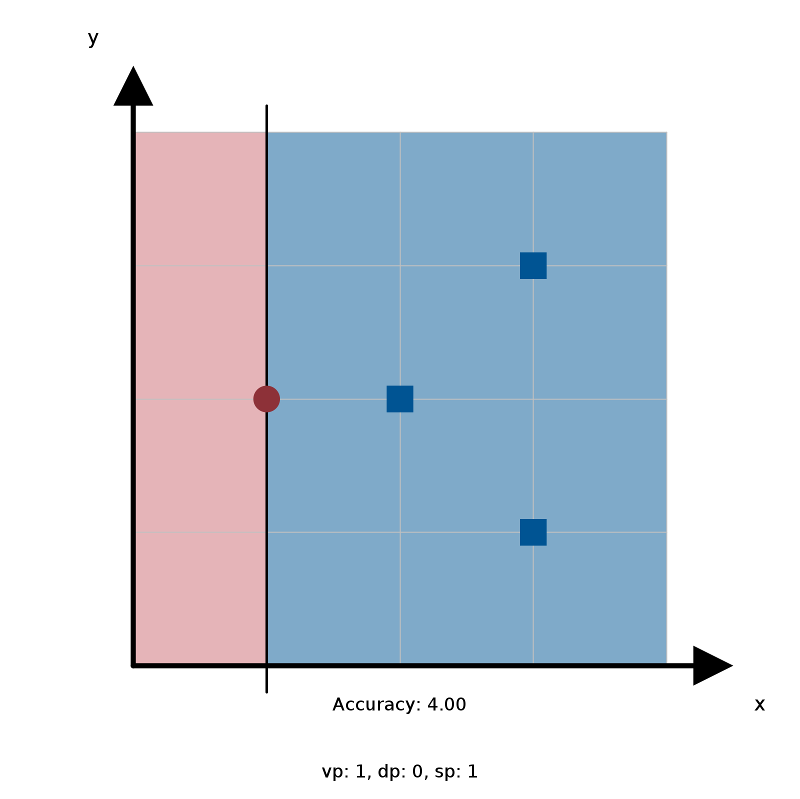
The visualizer displays the input points, the decision stump, the accuracy, and the values of $d_p$, $v_p$, and $s_p$. Compare these values to the ones in the corresponding .ans.txt file.
Part 3: Boosting Algorithm
As the name suggests, the weak learner is not a very powerful model on its own. You will now implement a better one using a technique called boosting: taking weak learners and improving (boosting) their quality. You will implement a simplified version of AdaBoost (short for Adaptive Boosting), which is an application of the multiplicative weights algorithm.
The input consists of $n$ labeled (non-reduced) transaction summaries (an $n \times m$ integer array input[][]), the $m$ map locations (a Point2D[] array of length $m$), and an integer $k$ (the number of clusters). Start by creating a Clustering object to map transaction summaries into arrays of length $k$ via dimensionality reduction. In the algorithm description below, "input" refers to these reduced transaction summaries (the $n \times k$ array); note that the API itself still takes the non-reduced $n \times m$ input.
AdaBoost is a version of multiplicative weights where each input point plays the role of an expert: its weight grows whenever it is hard to predict, forcing later weak learners to focus on it. The algorithm assigns a weight to each input point, represented as a double[] array of length $n$. This array is normalized so that its elements sum to $1$. Initially, all weights are set to $1/n$.
The boosting algorithm works in iterations. Each iteration proceeds as follows:
- Create a weak learner using the current weights and the input.
- For each input point, double its weight if the new weak learner mislabels it.
- Renormalize the weight array so that it sums to $1$ again (by dividing each weight by the sum of all weights).
Why double and renormalize?
We double the weight of mislabeled inputs to force the algorithm to try harder to predict them correctly in future iterations. Renormalization prevents numeric overflow: without it, after 100 mislabeled iterations a weight could reach $2^{100}$, which exceeds the range of a double.
Given a sample (an $m$-dimensional integer array corresponding to a new transaction summary), the boosted model outputs the majority vote over the predictions of the weak learners created in each iteration. Because each weak learner expects a $k$-dimensional input, the sample must first be reduced via the Clustering object before it can be passed to them. In case of a tie, output 0.
The BoostingAlgorithm data type
Implement a mutable data type BoostingAlgorithm with the following API:
public class BoostingAlgorithm {
// create the clusters and initialize your data structures
public BoostingAlgorithm(int[][] input, int[] labels, Point2D[] locations, int k)
// return the current weight of the ith point
public double weightOf(int i)
// apply one step of the boosting algorithm
public void iterate()
// return the prediction of the learner for a new sample
public int predict(int[] sample)
// unit testing
public static void main(String[] args)
}BoostingAlgorithm Requirements
BoostingAlgorithm(int[][] input, int[] labels, Point2D[] locations, int k)
- Behavior: Create the clusters from the locations and initialize data structures for boosting.
- Corner case: Throw
IllegalArgumentExceptionif any argument isnull, the lengths ofinput[][],labels[], andlocations[]are incompatible, the length ofinput[][]is zero, $k$ is not in the range $[1, m]$, or the values oflabels[]are not all either0or1. - Performance: Create one
Clusteringobject, then run in $O(nm)$ time.
weightOf(int i)
- Behavior: Return the current weight of the $i$th input point.
- Corner case: Throw
IllegalArgumentExceptionif $i$ is not in the range $[0, n - 1]$. - Performance: Constant time.
iterate()
- Behavior: Apply one step of the boosting algorithm: create a weak learner, double the weights of mislabeled inputs, and renormalize.
- Performance: Create one
WeakLearnerobject, then run in $O(n)$ time.
predict(int[] sample)
- Behavior: Return the majority-vote prediction for the given (non-reduced) sample. Reduce it first, then apply each weak learner. In case of a tie, return
0. - Corner case: Throw
IllegalArgumentExceptionif the argument isnullor has incompatible length. - Performance: Call
WeakLearner.predict()$T$ times andClustering.reduceDimensions()once, where $T$ is the number of iterations performed so far.
Testing tips
The following sample test client trains the model and calculates accuracy on both training and test data sets. It uses the DataSet utility class provided in the project folder.
Sample test client.
public static void main(String[] args) {
DataSet training = new DataSet(args[0]);
DataSet testing = new DataSet(args[1]);
int k = Integer.parseInt(args[2]);
int T = Integer.parseInt(args[3]);
int[][] trainingInput = training.getInput();
int[][] testingInput = testing.getInput();
int[] trainingLabels = training.getLabels();
int[] testingLabels = testing.getLabels();
Point2D[] trainingLocations = training.getLocations();
// train the model
BoostingAlgorithm model = new BoostingAlgorithm(
trainingInput, trainingLabels, trainingLocations, k
);
for (int t = 0; t < T; t++)
model.iterate();
// calculate the training data set accuracy
double trainingAccuracy = 0;
for (int i = 0; i < training.getN(); i++)
if (model.predict(trainingInput[i]) == trainingLabels[i])
trainingAccuracy += 1;
trainingAccuracy /= training.getN();
// calculate the test data set accuracy
double testingAccuracy = 0;
for (int i = 0; i < testing.getN(); i++)
if (model.predict(testingInput[i]) == testingLabels[i])
testingAccuracy += 1;
testingAccuracy /= testing.getN();
StdOut.println("Training accuracy of model: " + trainingAccuracy);
StdOut.println("Test accuracy of model: " + testingAccuracy);
}We provide two data sets: princeton_training.txt and princeton_test.txt, both using the locations from the Princeton map. Here is one example run:
~/Desktop/fraud> java-algs4 BoostingAlgorithm princeton_training.txt princeton_test.txt 5 80
Training accuracy of model: 0.9625
Test accuracy of model: 0.7375Note: your code might produce slightly different accuracy values depending on how your weak learner breaks ties. The training accuracy should be around 0.95 and the test accuracy around 0.7.
Deliverables
Project files
The file fraud.zip contains sample data files, test clients, and the DataSet utility class. It also contains feedback.txt, which you should fill out, and acknowledgments.txt, which you should complete with citations and collaboration information.
Submission
Submit Clustering.java, WeakLearner.java, and BoostingAlgorithm.java. Do not call any library functions other than those in
java.lang,
java.util,
and algs4.jar.
Finally, submit feedback.txt and acknowledgments.txt and answer the questions.
| File | Purpose |
|---|---|
Clustering.java |
Dimensionality reduction via MST-based clustering. |
WeakLearner.java |
Decision stump classifier. |
BoostingAlgorithm.java |
AdaBoost-based fraud detection model. |
feedback.txt |
Answers the assignment feedback questions. |
acknowledgments.txt |
Lists collaborators and external resources used. |
Advice
Suggested Approach
To help you work through the assignment, here is a suggested list of steps for how you might make progress. You don't have to follow this list to complete the assignment and in fact we recommend you don't look at it unless you get stuck.
List of steps.
-
Implement
Clustering. Go through the algorithm description and think about what instance variables you need and what temporary variables you need in the constructor to compute them. Only store as an instance variable what you truly need to support the instance methods. -
Implement
WeakLearnerusing an $O(kn^2)$ algorithm. Note thatWeakLearneris independent ofClustering, so you don't need to use it here. Loop over all possible values of $d_p$ ($k$ choices), $s_p$ ($2$ choices), and $v_p$ (only the $n$ coordinates that actually appear in the input matter), and for each combination compute the weight of correct predictions by iterating through all $n$ input points. -
Implement
BoostingAlgorithm. Create a singleClusteringobject in the constructor and aWeakLearnerevery timeiterate()is called. Store eachWeakLearner(e.g., in a linked list), since you need them in thepredict()method to compute predictions and take a majority vote. -
Optimize
WeakLearnerto $O(kn \log n)$. Once you have passed all tests except for the timing test onWeakLearner, think about how to avoid repeatedly iterating through all points for every possible decision stump. Hint: if you sorted the points by a certain coordinate, could you find the best decision stump for that coordinate in $\Theta(n)$ time? Keep your $O(kn^2)$ solution as a reference while implementing the more efficient one.