7. Chat126
Download project ZIP
| Submit to TigerFile
In this assignment, you will build a Markov model from an English text, then simulate it to generate stylized pseudorandom text. You will use symbol tables to store and look up $k$-grams efficiently.
Getting Started
- Review the textbook material on parameterized data type and generics (pages 566–570).
- Read the beginning of Section 4.4 (pages 582–586) on using symbol tables in client code.
- Consult the ST API API as needed.
- Review the precept exercises, especially
FrequencyTable.java. - Download and unzip chat126.zip
, then open the
chat126project in IntelliJ. - Review the partner collaboration policy.
Background
- Modern generative AI systems like ChatGPT produce text by modeling language and predicting what comes next.
- In this assignment, you will build a much simpler model—an order-k Markov model—that can still generate stylized text.
- Markov models are lightweight and fast to train and simulate.
- Claude Shannon proposed using Markov chains to model English text in 1948; here you’ll implement a playful variant to generating stylized pseudorandom text.
Markov model of natural language
A Markov model generates text one character at a time by sampling from probability distributions estimated from an input text.
-
Order 0. An order-0 Markov model chooses each character independently from a fixed distribution. We fit an order-0 model by counting character frequencies in the input text. For example, if the input text is
g a g g g a g a g g c g a g a a athen the model predicts
awith probability 7/17,cwith probability 1/17, andgwith probability 9/17. A typical generated sequence looks like:g a g g c g a g a a g a g a a g a a a g a g a g a g a a a g a g a a g ... -
Order $k$. Independence is a poor approximation for English: characters are strongly correlated (e.g.,
qis usually followed byu). An order-$k$ Markov model lets the next character depend on the previous $k$ characters, called a $k$-gram. For example, ifthis followed bye,i,a, andowith frequencies 60, 25, 10, and 5 (out of 100), then an order-2 model predicts that afterththe next letter isewith probability 3/5,iwith probability 1/4,awith probability 1/10, andowith probability 1/20. -
Generating text. To generate text from an order-$k$ model, start with an initial $k$-gram from the input. Repeatedly sample the next character according to the distribution for the current $k$-gram, append it to the output, and update the $k$-gram by dropping its first character and adding the sampled character.
-
Efficiency. A brute-force implementation that repeatedly searches the input text to find what follows the current $k$-gram is too slow for large inputs. Instead, we will preprocess the text and store the necessary counts so that we can sample the next character efficiently.
Q.What did Shannon propose?
Markov Language Model
Write a data type MarkovLM to represent a Markov model of order \(k\) based
on a given input text. Implement the following API:
public class MarkovLM {
// Creates a Markov language model of order k from the given text.
public MarkovLM(String text, int k)
// Returns the order k of the model.
public int order()
// Returns a string representation of the model (see below).
public String toString()
// Returns the number of times the k-gram occurs in the input text.
public int freq(String kgram)
// Returns the number of times character c follows the k-gram
// in the input text.
public int freq(String kgram, char c)
// Returns a character chosen at random, with probability proportional
// to the number of times each character follows the k-gram in
// the input text.
public char predictNext(String kgram)
// Tests this class by directing calling all instance methods.
public static void main(String[] args)
}
-
API. You must follow the prescribed API, with the given signatures. Do not add
publicmethods. -
Constructor. You may assume that the input text contains only ASCII characters (
charvalues between 0 and 127). -
String representation. Return a string representation of the model as illustrated below:
aa: a 1 g 1 ag: a 3 g 2 cg: a 1 ga: a 1 g 4 gc: g 1 gg: a 1 c 1 g 1Include one line for each $k$-gram that appears in the text. Each line contains the \(k\)-gram, followed by a colon; followed by each character that appears in the text immediately after that \(k\)-gram and the number of times it appears, with a space between each component. The $k$-grams must appear in lexicographic order, and the characters for each $k$-gram must appear in ASCII order.
-
Predict next character. The
predictNext()method must return a character that follows the given \(k\)-gram in the text, chosen at random with probability proportional to the number of times that character follows the $k$-gram. For example if"ga"appears 5 times—once followed byaand four times followed byg—thenpredictNext("ga")returnsawith probability 1/5 andgwith probability 4/5, independently on each call. -
Circular string. To avoid dead ends, treat the input text as a circular string: the first character succeeds the the last character. For example, if $k = 2$ and the input text is
"gagggagaggcgagaaa", then the model counts wrap-around $k$-grams as well. In particular, the frequency of"ag"is 5 (not 4) because one occurrence crosses the end of the string.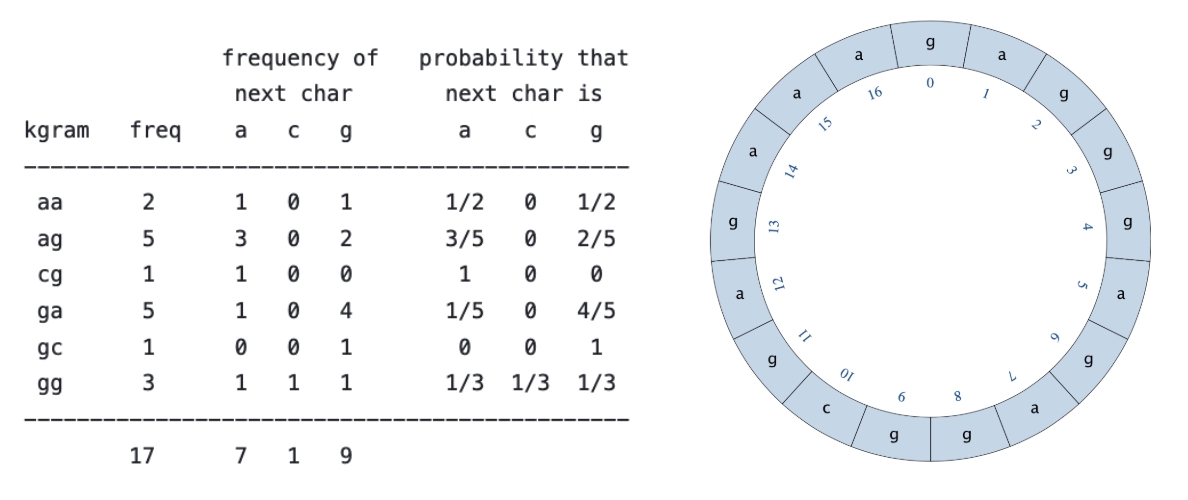
-
Corner cases. Throw appropriate exceptions for invalid arguments.
- In
freq()andpredictNext(), throw anIllegalArgumentExceptionifkgramis not of length $k$. - In
predictNext(), throw anIllegalArgumentExceptionifkgramdoes not appear in the input text. - We will not test your data type with
nullarguments.
- In
-
Performance requirements. Assume $k$ is a fixed constant. Let $n$ be the number of characters in the input text.
- The constructor must run in time proportional to $n \log n$ (or better)
order()must run in constant timepredictNext()and the twofreq()methods must run in time proportional to $\log n$ (or better)
To meet these requirements, use one or more symbol tables with $k$-grams as keys. and values that support efficient implementation of the two freq() methods.
Q.What is the worst-case running time for common symbol-table operations?
ST and java.util.TreeMap classes, the worst-case running time of
put(), get() and contains()/containsKey() is $\Theta(log n)$.Q.How do I extract a substring of a given string?
substring(). For example, s.substring(i, i + k) returns
the k-character substring of the string s, starting at i. Note that it
includes the left endpoint but excludes the right endpoint.Q.How do I generate a random index with probability proportional to its weight?
Review StdRandom.discrete(), which is overloaded:
- One takes a floating-point array
probabilities[]and returns indexiwith probability equal toprobabilities[i]. The array entries must be nonnegative and sum to 1. - The other takes an integer array
frequencies[]and returns indexiwith probability proportional tofrequencies[i]. The array entries must be nonnegative and not all zero.
Text Generator
A Markov chain is a stochastic process in which the next state depends only on the current state. For text generation, the state is a $k$-gram. At each step, choose the next character at random using the probabilities from the Markov model, then form the next state by appending that character and dropping the first character of the $k$-gram.
For example, if the current state is "ga" in the order-2 model above,
then the next character is a with probability $1/5$ and g with probability $4/5$.
One possible trajectory (nine transitions) is:
$$ ga \rightarrow ag \rightarrow gg \rightarrow gc \rightarrow cg \rightarrow ga \rightarrow ag \rightarrow ga \rightarrow aa \rightarrow ag $$
Treating the input text as a circular string ensures that the Markov chain never gets stuck in a state with no possible next character.
To generate text from an order-$k$ model, start in the initial state
given by the first $k$ characters of the input text.
Then perform $T - k$ transitions, printing the sampled character at each step.
For example, if $k = 2$ and $T = 11$, the following trajectory could produce the output gaggcgagaag:
trajectory: ga --> ag --> gg --> gc --> cg --> ga --> ag --> ga --> aa --> ag
output: ga g g c g a g a a g
Write a client program Chat126 that:
- takes two integer command-line arguments $k$ and $T$;
- reads the input text from standard input;
- builds an order-$k$ Markov model from the input text; and
- prints $T$ characters generated by simulating a trajectory through the corresponding Markov chain, starting from the first $k$ characters of the input text..
~/Desktop/chat126> more input17.txt gagggagaggcgagaaa ~/Desktop/chat126> java-introcs Chat126 2 11 < input17.txt gaggcgagaag ~/Desktop/chat126> java-introcs Chat126 2 11 < input17.txt gaaaaaaagag ~/Desktop/chat126> java-introcs Chat126 0 50 < input17.txt gaaagaacagcagacgacggaagaaggaggaaaaggaggggaggggggag
-
Corner cases. You may assume that the length of the text is at least $k$ and $T \geq k$.
-
Performance requirement. If $k$ is a fixed constant, then the running time of Chat126 must be proportional to $n \log n + T \log n$ (or better), where $(n$ is the number of characters in the input text and $(T$ is the number of characters in the output.
Click here to show possible progress steps for MarkovLM.
Implementing MarkovLM.java
- Review precept exercises, especially
FrequencyTable, as well asIntegerSort.java. - Create one or more instance variables to support the two
freq()methods. One strategy is to maintain two symbol tables—one for the one-argumentfreq()method and one for the two-argumentfreq()method.
- For each $k$-gram (a string), the first symbol table tells you how many times it appears in the text (an integer).
- For each $k$-gram (a string), the second symbol table tells you how many times each ASCII character succeeds the $k$-gram in the text (an array of 128 integers).
- Character (i.e.,
charvalues) can be used as an index into an array. In Java, characters are 16-bit (unsigned) integers; they are promoted tointvalues in any context that expects one. For example,array['c']is equivalent toarray[99]because the ASCII code for'c'is 99. - You can avoid hardwiring the constant 128 by using a static instance variable:
private static final int ASCII = 128; - This code should appear inside the class block, but before any instance variables or methods. By convention, constant variable names should be ALL_UPPERCASE. The
staticmodifier means that every instance method will refer to the same variable (as opposed to instance variables, for which there is one variable per object); thefinalmodifier means that you can’t change its value, once initialized.
- Write the constructor to create the circular version of the input text. Then initialize and populate your symbol tables, using the symbol table methods
contains(),get(), andput(). This will be a substantial amount of code, relative to the other methods in this class.
- Do not save the original text (or the circular text) as an instance variable because no instance method will need this information after the symbol table is initialized.
- There are a number of approaches for emulating the circular text. One way is to append the first $k$ characters of the input text to the input text.
- Test: In the
main(), try creating someMarkovLMobjects. For example:String text1 = "banana"; MarkovLM model1 = new MarkovLM(text1, 2); ... String text2 = "gagggagaggcgagaaa"; MarkovLM model2 = new MarkovLM(text2, 2); - Write the
toString()method. Use an enhanced for loop to access each key–value pair in your symbol table and aStringBuilderto generate the requiredStringvalue. See theFrequencyTable.javafrom precept for an example. - Test the constructor and
toString() method: This can help you debug small test cases. In themain(), print someMarkovLMobjects. For example:String text1 = "banana"; MarkovLM model1 = new MarkovLM(text1, 2); StdOut.println(model1); ... String text2 = "gagggagaggcgagaaa"; MarkovLM model2 = new MarkovLM(text2, 2); StdOut.println(model2);
- Sample output from the code snippet above:
ab: a 1 an: a 2 ba: n 1 na: b 1 n 1 aa: a 1 g 1 ag: a 3 g 2 cg: a 1 ga: a 1 g 4 gc: g 1 gg: a 1 c 1 g 1 - You can insert a line break in a
Stringby using the characters\n. For example, if you print"ab\ncd",abandcdwill appear on separate lines.
- Write the
order()method. This should be a one-liner. - Using the symbol table instance variables, write the two
freq()methods. - Use the
main()provided above to test your code before continuing. In themainmethod, you should add more tests of the constructor,order(), andfreq()methods. - Write the
predictNext()method. To generate a random character with probability proportional to its frequency you may call either of the twoStdRandom.discrete()methods. - It may not be obvious from your final results whether
predictNext()is working as intended, so be sure to test it thoroughly. Next, test your completeMarkovLMdata type before continuing. (See Testing YourMarkovLM.javaImplementation below.)
Click here to show possible progress steps for Chat126.
Implementing Chat126.java
- Read in
kandTfrom the command line; read the input text from standard input. - Create a
MarkovLMobject of orderkusing the input text. - To generate a trajectory of length
T, use the firstkcharacters in the input text as the initial \(k\)-gram and print the initial \(k\)-gram. Then, repeatedly generate and print a new random character according to the Markov model and update the \(k\)-gram to store the lastkcharacters printed. - Make sure to test your program on large inputs (we provide several), large outputs, and different values of
k. - Some FAQs:
- Should my program generate a different output each time I run it? Yes.
- How can I read in the input text from standard input? Use
StdIn.readAll(). Do not remove whitespace. - My random text ends in the middle of a sentence. Is that OK? Yes, that’s to be expected.
- After executing the program, the command prompt appears on the same line as the random text. Is that OK? Yes. It’s because the random text does not end with a newline character. If you want to add a call to
StdOut.println()at the end of your program, that’s fine—we promise not to deduct. - What does this message mean: The local variable ‘T’ must start with a lowercase letter and use camelCase? Since
Tis a constant, you should declare it asfinal, e.g.,final int T = .... Alternatively, you can rename the constant using a variable name that is more than one character. - For which values of \(k\) should my program work? It should work for all well defined values of \(k\), from 0 up to, and including, the length of the input text. As \(k\) gets larger, your program will use more memory and take longer.
- My program is slow when \(T\) is large because I am concatenating the \(T\) characters, one at a time, to form string of length \(T\)). What else can I do? Do you need to form the entire string? Why not print the characters, one at a time, as you generate them?
- I get an
OutOfMemoryException. How do I tell Java to use more of my computer’s memory? Depending on your operating system, you may have to ask the Java Virtual Machine for more main memory beyond the default. The500mmeans 500MB, and you should adjust this number depending on the size of the input text.java-introcs -Xmx500m Chat126 7 1000 < input.txt
Testing
Testing Your MarkovLM.java Implementation
We provide a main() as a start to your testing. You will need to provide more tests.
public static void main(String[] args) {
String text1 = "banana";
MarkovLM model1 = new MarkovLM(text1, 2);
StdOut.println("freq(\"an\", 'a') = " + model1.freq("an", 'a'));
StdOut.println("freq(\"na\", 'b') = " + model1.freq("na", 'b'));
StdOut.println("freq(\"na\", 'a') = " + model1.freq("na", 'a'));
StdOut.println("freq(\"na\") = " + model1.freq("na"));
StdOut.println();
String text3 = "one fish two fish red fish blue fish";
MarkovLM model3 = new MarkovLM(text3, 4);
StdOut.println("freq(\"ish \", 'r') = " + model3.freq("ish ", 'r'));
StdOut.println("freq(\"ish \", 'x') = " + model3.freq("ish ", 'x'));
StdOut.println("freq(\"ish \") = " + model3.freq("ish "));
StdOut.println("freq(\"tuna\") = " + model3.freq("tuna"));
}
If your method is working properly, you will get the following output:
java-introcs MarkovLM
freq("an", 'a') = 2
freq("na", 'b') = 1
freq("na", 'a') = 0
freq("na") = 2
freq("ish ", 'r') = 1
freq("ish ", 'x') = 0
freq("ish ") = 3
freq("tuna") = 0
To test predictNext(), write a loop that calls predictNext() repeatedly, and count how many times a particular character is returned. For example, with model1 above, predictNext("na") should return b about one-half of the time; with model3 above, predictNext("fish") should return o about one-quarter of the time.
Of course, you should try to define and test other models.
Generating Text Using Different Inputs and Orders
Once you get the program working, test it on different inputs of different sizes and different orders. Does increasing the order have the effect you expect? Try your model on something that you have written or some other text you know well. Make sure to test both long inputs (we provide several) and long outputs. Here are a couple of examples (click on the ► icon to expand to expand/collapse):
Example 1 Input: Speech to the Class of 2018
Good afternoon and welcome to Opening Exercises. What a special pleasure it is to greet Princetons Great Class of 2018! I also offer a warm welcome to our new graduate students, faculty and staff members, and all of you who are returning to campus after the summer.
Today we carry on a tradition that dates back at least to 1802, when Nassau Hall was the site of an opening exercise for Princeton students. The event switched to other sites before moving in 1929 to the University Chapel, where we gather today. Todays interfaith ceremony is far different from the Christian services that greeted students in 1929, but the chapels soaring architecture and inspirational spaces continue to invite all of us, whatever our religious or ethical traditions might be, to reflect on the larger purposes that should guide our community as we begin another year on this glorious campus.
Today you join the ranks of students who have left their marks on the Princeton campus and the world for generations through their intellect, creativity and passion. You, the 1,312 members of the Class of 2018, are an extraordinarily accomplished, inspiring and diverse group. You hail from 46 states, as well as the District of Columbia. You come from 50 countries outside of the United States from Chile to the Czech Republic, from Iceland to India, from Nigeria to New Zealand. You grew to become upstanding, compassionate citizens in Happy Valley, Oregon, and Niceville, Florida. You weathered the ups and downs of life in Boiling Springs, Pennsylvania, and Frostburg, Maryland. And you learned to appreciate the lyrical majesty of language in Ho Ho Kus, New Jersey, and Oologah, Oklahoma.
Example 1 output: random Eisgruber, using order 7 model
java-introcs Chat126 7 798 < opening-exercises.txt
Good afternoon and welcome to a universities around you here.
I often ask Princeton is a truly global institution. As scholars who matter most to you. And you here.
I often ask Princeton you have come to our social natures, and, more specifically, with drums and choirs and distinguished teachers, whose contributions will become upstanding.
This Universitys GREAT CLASS OF 2018! Welcome new members play indispensable roles in helping our Universitys GREAT CLASS OF 2018! I also offer insignificant, or puzzling, or uninteresting, or unsympathetic may turn out to be discourse in all disciplines here as rich with meaningful, not just of any story, can make it easy to feel without knowing exactly what he was destined to appreciate the lyrical majesty of language in Ho Ho Kus, New Jersey, and
Example 2 Input: As you Like It, Act 2
[Enter DUKE SENIOR, AMIENS, and two or three Lords, like foresters]
DUKE SENIOR Now, my co-mates and brothers in exile, Hath not old custom made this life more sweet Than that of painted pomp? Are not these woods More free from peril than the envious court? Here feel we but the penalty of Adam, The seasons’ difference, as the icy fang And churlish chiding of the winter’s wind, Which, when it bites and blows upon my body, Even till I shrink with cold, I smile and say ‘This is no flattery: these are counsellors That feelingly persuade me what I am.’ Sweet are the uses of adversity, Which, like the toad, ugly and venomous, Wears yet a precious jewel in his head; And this our life exempt from public haunt Finds tongues in trees, books in the running brooks, Sermons in stones and good in every thing. I would not change it.
AMIENS Happy is your grace, That can translate the stubbornness of fortune Into so quiet and so sweet a style.
DUKE SENIOR Come, shall we go and kill us venison? And yet it irks me the poor dappled fools, Being native burghers of this desert city, Should in their own confines with forked heads Have their round haunches gored.
Example 2 output: random Shakespeare, using order 6 model
java-introcs Chat126 7 1135 < as-you-like-it.txt
DUKE SENIOR Now, my co-mates and thus bolden’d, man, how now, monsieur Jaques, Unclaim’d of his absence, as the holly! Though in the slightest for the fashion of his absence, as the only wear.
TOUCHSTONE I care not for meed! This I must woo yours: your request than your father: the time, That ever love I broke my sword upon some kind of men Then, heigh-ho! sing, heigh-ho! sing, heigh-ho! sing, heigh-ho! unto the needless stream; ‘Poor deer,’ quoth he, ‘Call me not so keen, Because thou the creeping hours of the sun, As man’s feasts and women merely players: Thus we may rest ourselves and neglect the cottage, pasture? Enter DUKE FREDERICK Can in his time in my heartily, And have me go with your fortune In all this fruit Till than bear the arm’s end: I will through Cleanse the uses of the way to look you. Know you not, master, Sighing like upon a stone another down his bravery is not so with his effigies with my food: To speak my mind, and inquisition And unregarded age in corners throat, He will come hither: He dies that hath engender’d: And you to the bed untreasured of the brutish sting it.
Submission
Upload all required files to TigerFile :
MarkovLM.javaChat126.javareadme.txtacknowledgments.txt
Include in your readme.txt two of the most entertaining language-modeling fragments that you discover.
Grading breakdown
| Files | Points |
|---|---|
| MarkovLM.java | 26 |
| Chat126.java | 10 |
| readme.txt | 4 |
| Total | 40 |
Challenges
Challenge for the bored 1.
The current assignment only handles ASCII characters. However, many text collections use Unicode characters, such as those with diacritic marks (e.g.: ā ă ą ç é ē î ï ĩ í ĝ ġ ń ñ ö š ŝ ś û ů ŷ Á Ç) and other characters (e.g., 😀 ł đ ħ œ ⺆).
Extend your solution so that it replaces and/or removes such Unicode characters in your text. Hint - use the API provided in the ToASCII.java class. Try your solution on a text that contains Unicode.
Challenge for the bored 2.
Extend your solution to handle Unicode text, not just ASCII.
Challenge for the bored 3.
Imagine you receive a message where some of the characters have been corrupted by noise. We represent unknown characters by the ~ symbol (and assume the character ~ does not appear in the original text). Devise a scheme based on the Markov model to determine the most likely value for each corrupted character. Assume unknown characters are at least \(k\) characters apart (and appear at least \(k\) characters away from the start and end of the message). Test your new method by writing a client program FixCorrupted.java that takes as arguments the model order and the noisy string. The program prints the most likely original string:
Original: it was the best of times, it was the worst of times.
Noisy: it w~s th~ bes~ of tim~s, i~ was ~he wo~st of~times.
java-introcs FixCorrupted 4 "it w~s th~ bes~ of tim~s, i~ was ~he wo~st of~times." < wiki_100k.txt
it was the best of times, it was the worst of times.
Enrichment
Click each item to expand.
Click again to collapse the answer.What is the relationship between Markov models and LLMs for generating text?
- We actually asked ChatGPT this question, and here’s its response (slightly edited):
- Markov models and Large Language Models (LLMs) are both used for generating text but operate on different principles.
- Markov Models: These are based on the Markov property, which states that the future state of a system depends only on its present state, not on the sequence of events that preceded it. In the context of text generation, a Markov model predicts the next word in a sequence based current k-gram.
- Large Language Models (LLMs): These are more sophisticated models based on neural networks, particularly variants like GPT (Generative Pre-trained Transformer) models. LLMs leverage deep learning techniques to capture complex patterns and dependencies in text data. They are trained on large corpora of text and can generate coherent and contextually relevant sequences of text. Unlike Markov models, LLMs do not rely solely on fixed-length context windows but instead learn contextual representations of words and phrases based on their entire input sequence.
- While both Markov models and LLMs can generate text, LLMs generally produce more fluent and contextually appropriate text due to their ability to capture long-range dependencies and contextual nuances. However, Markov models are simpler and more interpretable, making them suitable for certain text generation tasks, especially when computational resources are limited.
What is the origin of the Markov text generator?
It was first described by Claude Shannon in 1948. The first computer version was apparently written by Don P. Mitchell, adapted by Bruce Ellis, and popularized by A. K. Dewdney in the Computing Recreations section of Scientific American. Brian Kernighan and Rob Pike revived the program in a University setting and described it as an example of design in The Practice of Programming. The program is also described in Jon Bentley’s Programming Pearls.What else can I do with a random text generator?
One former COS 126 student recited its output during the Frist filibuster.Some other interesting topics.
- We are implementing the model Shannon described in his landmark paper. But the one reads until this letter is encountered method in his quote on the assignment page is, ironically, not a statistically accurate example of his model. If we run your program with input
wawawaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaawythenwshould be followed bya75% of the time, while the read until model will followwwithaonly 15% of the time. What would be involved in simulating this other model? Which one do you think gives more realistic text? - Here’s a website that generates pseudo-random computer science papers. It uses something called a context-free grammar instead of a Markov chain, but otherwise is similar in spirit to what you are doing on this assignment.
- Here are Garfield comics generated by a Markov chain.
Copyright © 2005–2025 Robert Sedgewick and Kevin Wayne, All Rights Reserved