See instructions on the assignments page on how and when to turn these in. Be sure to show your work and justify all of your answers.
The written portion of the homework can be found here.
This assignment is about using the Markov Chain Monte Carlo technique (also known as Gibbs Sampling) for approximate inference in Bayes nets. The main components of the assignment are the following:
Optionally, you can also implement and test other inference procedures discussed in class or the book.
The first part of the assignment is to implement the MCMC algorithm. The purpose of this algorithm is to estimate the probability distribution of one variable in a Bayes net, given the settings of a subset of the other variables. As described below, we are providing code for reading in a Bayes net and a query to the Bayes net from files. Your code should then run MCMC some specified number of iterations to estimate the required probability.
Since MCMC is a randomized, iterative algorithm, the actual number of iterations needed to estimate probabilities is an important (and not fully understood) issue, and one that will be explored as part of this assignment.
Systematic or random updates: In the version of MCMC given in R&N, the variables are updated systematically by cycling through them in order. In class, we instead looked at a version in which a single randomly selected variable is updated on each iteration. Please use the random-update version given in class. (For extra credit, you are welcome to also experiment with a version that makes systematic updates.)
Sampling from a probability distribution: For one part of the MCMC algorithm, you will need to sample randomly from an arbitrary distribution over a small set of possible values. Here is a simple way to do this, given access to the kind of (pseudo-)random numbers provided by Java. Suppose we want to choose among four values, A, B, C and D, and suppose further that we want to pick A with probability 0.22, B with probability 0.43, C with probability 0.05 and D with probability 0.30. In Java, it is possible to obtain (approximately) uniformly distributed random numbers in the range [0, 1), where [a, b) denotes the set of real numbers bigger than or equal to a, and (strictly) smaller than b. Let r be such a random number. Then, to sample according to the given distribution over A, B, C and D, we just need to pick A if r is in [0.00, 0.22), B if r is in [0.22, 0.65), C if r is in [0.65, 0.70), and D if r is in [0.70, 1.00). Because r is equally likely to be any real number in [0,1), the chance of choosing each of the four values is simply equal to the length of the interval that we associated with it (for instance, the chance of choosing B is the length of the interval [0.22, 0.65), which is 0.43). Thus, each of the four values will be selected with exactly the desired probability.
If implemented properly, this procedure, when selecting randomly among k values, can be made to run in O(k) time. For generating random numbers, see the documentation for the Random class which is provided as part of the Standard Java Platform.
Once your MCMC implementation is working and has been tested for correctness, the second part of the assignment is to try it out on a number of Bayes nets and queries, some of which we are providing, and others that you are asked to create.
Specifically, we are asking that you try the following, and that you answer the listed questions.
Earthquakes and burglar alarms
As a "sanity check" to be sure your code is working, start by running MCMC on the "earthquakes and burglar alarms" Bayes net discussed in class and given in R&N Figure 14.2. This Bayes net is provided in the file alarm.bn. Specifically, answer the following:
Automobile insurance
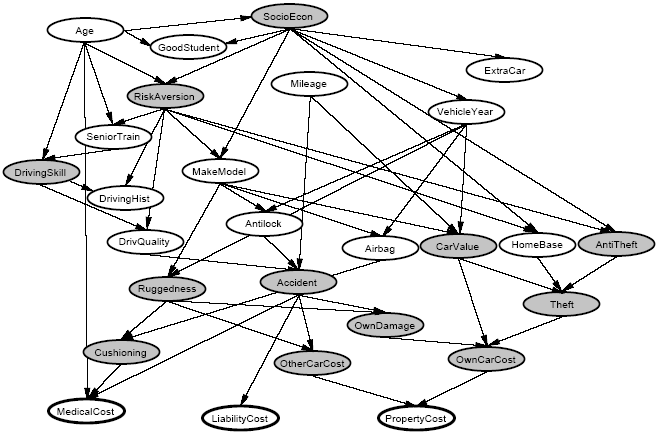
The next Bayes net attempts to estimate the risk posed by an individual seeking car insurance. In other words, the network attempts to relate variables like the age and driving history of the individual to the cost and likelihood of property damage or bodily injury. Here is a graphical depiction of the network:
The 12 shaded variables are considered hidden or unobservable, while the other 15 are observable. The network has over 1400 parameters. An insurance company would be interested in predicting the bottom three "cost" variables, given all or a subset of the other observable variables. For instance, for an adolescent driving a car with about 50,000 miles and no anti-lock brakes, we can estimate the cost of property damage to have the following distribution:
| Estimated Cost | Probability |
| $1,000 | 0.457 |
| $10,000 | 0.343 |
| $100,000 | 0.173 |
| $1,000,000 | 0.028 |
The network has been provided in the file insurance.bn.
Leader and followers
Next, we will explore the convergence properties of MCMC on a very simple family of Bayes nets. Theoretically, MCMC will converge to the right answer asymptotically, that is, as the number of iterations becomes very large. However, in practice, it is not always clear how many iterations actually suffice, as this example demonstrates.
Each network in this family has a single "leader" variable, and some number of "follower" variables. The idea is that the leader selects a bit at random (0 or 1 with equal probability), and then all of the followers choose their own bits, each one copying the leader's bit with 90% probability, or choosing the opposite of the leader's bit with 10% probability. (For instance, to be concrete, the "leader" might be Congressman Tom DeLay, and the "followers" might be the other Republican Representatives from Texas; the bits then might represent voting for or against a particular bill. We are assuming that each of the follower Representatives follows Tom D.'s lead in how they vote on this bill with 90% probability.)
Here is the topology of such a network with four followers:
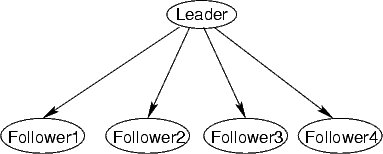
Leader-follower networks with k followers have been provided in the files leader-follower-k.bn for k = 5, 10, 15, 20, 25, 30, 35, 50.
The query we will study in each case is rather trivial: We will simply ask what the (marginal) probability distribution is for the leader variable, in the absence of any evidence (i.e., none of the other variables have been set to specified values). This query is encoded in the file leader-follower.qry.
Here are things to try and questions to answer:
Your own Bayes net
The last part of the assignment is to devise a Bayes net and at least one query of your own creation. Try to think of a network that models something interesting and/or (semi)realistic, such as the insurance network or burglar alarm networks studied above. Your network does not have to be large and complicated -- even a quite small network can be interesting. Your network can model anything you wish. Be creative! If you have difficulty coming up with your own ideas, you can think about designing a network to model something discussed in the book or in class or in one of the written exercises (however, you should not take an idea for which a network has already been given in class or in the book, such as the "burglar alarm" network). In addition to the topology of the network, you will need to estimate all of the probabilities for all of the conditional probability tables defining the network. You can make these numbers up however you wish, but you should attempt to estimate these numbers based on your intuition or knowledge of the problem as best as you can.
Once you have designed your network, choose one or more queries to test on it. Try to choose a Bayes net and queries whose answers are non-obvious (even approximately), or which reveal something interesting about the nature of probabilistic reasoning (such as the example in written exercise 3 above).
Finally, you should answer the following:
Call the Bayes net and query files you create mynet1.bn and mynet1.qry. If you create others, name them in a similar fashion.
For extra credit, you can choose optionally to implement one other algorithm for exact or approximate inference, including any of the algorithms discussed in R&N Sections 14.4 and 14.5. You also can try out variations of MCMC, for instance, with systematic rather than random updating of the variables. If you try any of these, you should experiment with them on a number of Bayes nets in a manner similar to that described above, and you should write up your results and observations. You might want to include comparisons to MCMC, and trade offs of running time versus accuracy of results.
We are providing a class called BayesNet for reading in a description of a Bayes net from a data file. A description of the topology of the Bayes net is stored in public fields of the BayesNet object, while the conditional probability tables are accessed using a public method. Internally, variables are identified with the integers 0, 1, 2, ..., up to (but not including) the number of variables. The values that each variable can take are also given as integers in a similar manner. Here are the public fields of a BayesNet object: numVariables is the number of variables; varName[i] is the name (as a String) of variable i; numValues[i] is the number of values that variable i can take, and valueNames[i][j] gives the name of variable i's j-th value; numParents[i] is the number of parents of variable i; and parents[i][] is an array listing the parents of variable i.
Access to the conditional probabilities which define the Bayes net is via the public method getCondProb(). This method returns the conditional probability of a specified variable x taking a particular value, given the settings of variable x's parents. The first argument to this method is simply the variable x whose (conditional) probability is to be looked up. The second argument vals[] is an integer array of length equal to the total number of variables, where vals[i] is a provided value for variable i. Values must be provided in this array for x and for all of x's parents; all other values in this array will be ignored. The value returned by the method is the conditional probability of variable x taking the value vals[x], given that all of x's parents are set to the values specified in the vals[] array.
A BayesNet object can be constructed using a constructor which takes as argument the name of the file containing a description of the Bayes net. These files should have a format like this one, alarm.bn, which encodes the "burglar alarm" network (R&N Figure 14.2):
variable Burglary t f
variable Earthquake t f
variable Alarm t f
variable JohnCalls t f
variable MaryCalls t f
probability Burglary
0.001 0.999
probability Earthquake
0.002 0.998
probability Alarm | Burglary Earthquake
t t 0.95 0.05
t f 0.94 0.06
f t 0.29 0.71
f f 0.001 0.999
probability JohnCalls | Alarm
t 0.90 0.10
f 0.05 0.95
probability MaryCalls | Alarm
t 0.70 0.30
f 0.01 0.99
The first line specifies the name of a variable called "Burglary" which can take two values called "t" and "f". Throughout the program, the ordering of the values of this variable should follow the ordering given here in the .bn file; thus, in this case, "t" will be associated with value 0 for the Burglary variable, and "f" with value 1. The next several lines in the first block similarly define variables and their values.
The next block (beginning "probability Burglary")
specifies the probability of each of Burglary's two values: t has probability
0.001 and f has probability 0.999. Note that, because Burglary
has no parents, nothing follows the word "Burglary" in this block. Skipping
ahead, the fourth block (beginning "probability Alarm") specifies that variable
Alarm's parents are Burglary and Earthquake. The lines that follow within
this block define Alarm's conditional probability table. For instance, the
second line gives the probability distribution of Alarm when Burglary is set to
value
We also are providing a Query class for reading in queries from files or from standard input. The query itself is stored in public fields of the Query object. Queries are always of the form: what is the probability distribution of some particular variable, given the settings of some other variables (the so-called evidence variables)? Accordingly, Query objects have two public fields: queryVar is the variable whose value is being queried, and evidence[] is an array specifying the settings of a subset of the other variables. More specifically, evidence[i] gives the value that variable i is to be set to if it is one of the evidence variables for this query; otherwise, if variable i is not an evidence variable, then evidence[i] is set to -1.
Here is an example file, alarm1.qry, showing the format of query files:
Burglary
JohnCalls t
MaryCalls t
The first line specifies the query variable. Each of the subsequent
lines specifies an evidence variable and the value to which it should be set.
This particular query asks for the probability distribution of the
The class RunMcmc provides a main that you can use for testing, or you may wish to write your own (although it is still required that your code work with the main that we provided). Once MCMC has been implemented, this main simply runs MCMC for some number of rounds, printing partial results with a specified frequency, on a given Bayes net and query. For instance, the following command might produce the following output (obviously, the output will be different each time that the algorithm is run since MCMC is a randomized algorithm):
> java RunMcmc alarm.bn alarm1.qry 100 20
20 0.85000000 0.15000000
40 0.47500000 0.52500000
60 0.31666667 0.68333333
80 0.37500000 0.62500000
100 0.37000000 0.63000000
>
The command-line arguments are: name of the file describing the Bayes net; name of the file describing the query; maximum number of iterations; frequency with which results should be printed. Here, the specified Bayes net and query correspond to the example files given above. The first line of the output means that, after 20 iterations, the estimated probability that Burglary equals t or f is 0.85 or 0.15, respectively. Similarly for the lines that follow.
The code and all data files are available here, or as a single zip file here. Data is included in the data subdirectory. This code should work with either Java 1.4.2 or Java 1.5.0. However, it will cause (non-fatal) warning messages to appear when compiling using 1.5.0. If you are using 1.5.0 and you want to avoid these, you can use the slightly modified code in the 1.5.0 subdirectory instead.
Documentation on the provided Java classes is available here.
As a general reminder, you should not modify any of the code that we are providing, other than template files, or unless specifically allowed in the instructions.
Your job is to fill in the MCMC algorithm in the template file Mcmc.java. You need to first fill in a constructor which will take as input a BayesNet and Query, and which will initialize all data structures you are using appropriately, but which will not actually run MCMC. You then need to fill in the method runMoreIterations(). This method takes an integer argument specifying how many additional iterations of MCMC are to be executed. So, calling the constructor does not run MCMC, but only sets everything up. Calling runMoreIterations(1000), for instance, would run MCMC for 1000 iterations. Calling runMoreIterations(1000) again would run MCMC for an additional 1000 iterations. It is therefore imperative that you save the state of the current run of MCMC between calls to runMoreIterations(); do not re-start your run of MCMC each time that this method is called.
Each call to runMoreIterations() should return a double array specifying the probability distribution over the values of the query variable.
Using moodle, you should turn in the following electronically:
In addition, you should turn in the following in hard copy with your written exercises:
We will automatically test your code on Bayes nets and queries, possibly different from those that we provided. Your grade will depend largely on getting the right answers. In addition, your code should be efficient enough to run reasonably fast (easily executing MCMC at around a million iterations every couple seconds on a fast machine). Your code should not terminate prematurely with an exception (unless given bad data, of course); code that does otherwise risks getting no credit for the automatic testing portion of the grade. As always, you should follow good programming practices, including documenting your code enough for the TA to be able to read and understand it. Creativity, especially in the design of your own Bayes net and query, will be one component of your grade.
Your answers to the questions above should be clear, concise, complete, correct, thoughtful and perceptive.
The (fictional) insurance network was extracted from the paper "Adaptive Probabilistic Networks with Hidden Variables" by J. Binder, D. Koller, S. Russell and K. Kanazawa (Machine Learning, 29, 213–244 (1997)).