The Content-Aware Similarity
Search (CASS) project investigates research issues in searching, clustering,
and classification, and management for feature-rich, non-text data types.
Current research topics include:
- Sketch construction
techniques. Address the issue that feature vectors of feature-rich data
objects are high dimensional. The goal is to develop practical
algorithms to construct sketches to substantially reduce the dimensions
and sizes of feature vectors while achieving high-quality similarity
searches.
- Efficient filtering and
indexing methods. Indexing and filtering large feature-rich datasets are
challenging because noisy data require similarity match and similarity
search and indexing data structures for exact match do not apply. The
goal is to investigate novel data structures and algorithms to filter
and index for similarity search of large datasets.
- Similarity search of
multiple data types. Develop understanding of similarity search of
various data types including images, audio, video, 3D shapes, scientific
sensor data and documents. We are also interested in continuous archived
data and data with multiple modalities.
- Toolkit for similarity
search. Most similarity search efforts are domain specific. Our goal is
to design and implement a toolkit that can be used to construct search
engines for various data types by plugging in specific data
segmentations, feature extractions and distance calculation modules.
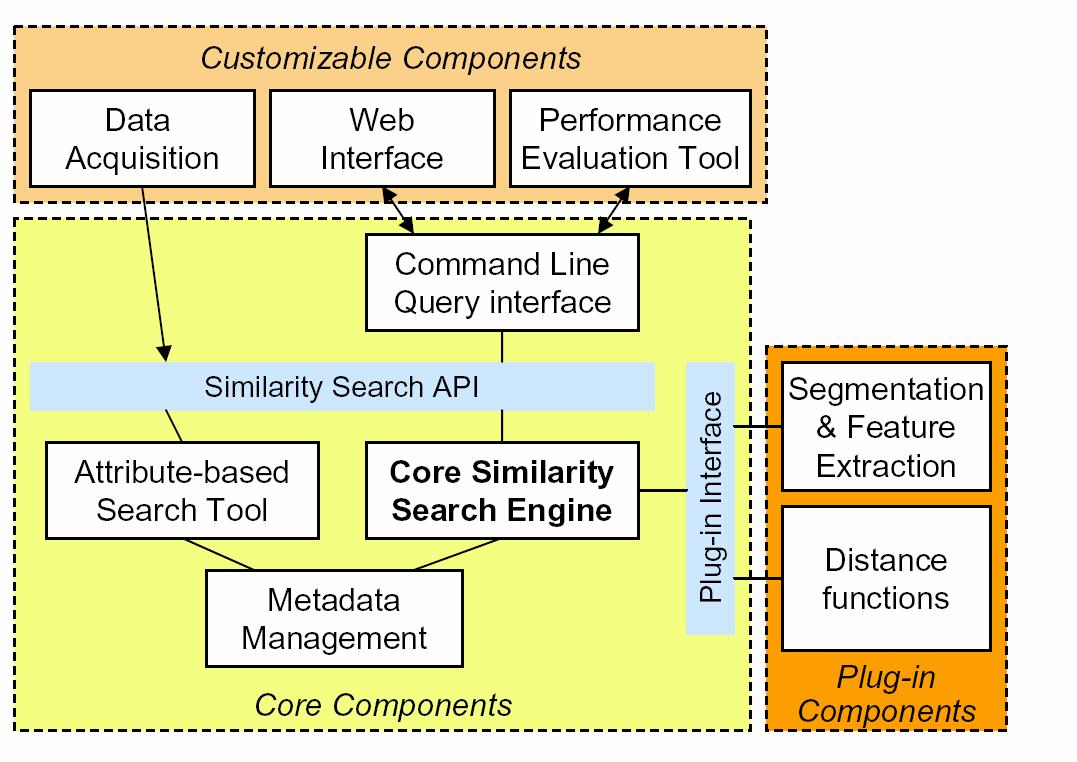
We have built an initial toolkit
called Ferret which has been used with four data types including images,
audio recordings, 3D shapes, and genomic microarray data. Below is the
architecture design of the Ferret toolkit. Click here
to see some demos and snapshots of the search systems built using the Ferret
toolkit.
|