Speculative Recovery: Cheap, Highly Available Fault Tolerance with Disaggregated Storage
The ubiquity of disaggregated storage in cloud computing has led to a nascent technique for fault tolerance: instead of utilizing application-level replication, newly-launched backup instances recover application state from disaggregated storage (REDS) after a primary’s failure. Attractively, REDS provides fault tolerance at a much lower cost than traditional replication schemes, wherein at least two instances are running. Failover in REDS is slow, however, because it sequentially first detects primary failure and only then starts recovery on a backup.
We propose speculative recovery to accelerate failover and thus increase the availability of applications using REDS. Instead of proceeding with failover sequentially, speculative recovery safely and efficiently parallelizes detecting primary failure and running recovery on a backup, by employing our new super and collapse primitives for disaggregated storage. Our implementation and evaluation of speculative recovery demonstrate that it considerably reduces failover time.
-

Paper
In ATC 2022
-
Code
On GitHub
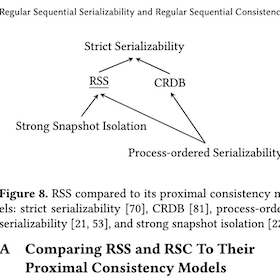
Regular Sequential Serializability and
Regular Sequential Consistency
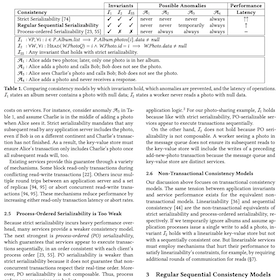
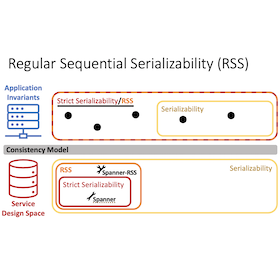
Strictly serializable (linearizable) services appear to execute transactions (operations) sequentially, in an order consistent with real time. This restricts a transaction’s (operation’s) possible return values and in turn, simplifies application programming. In exchange, strictly serializable (linearizable) services perform worse than those with weaker consistency. But switching to such services can break applications. This work introduces two new consistency models to ease this trade-off: regular sequential serializability (RSS) and regular sequential consistency (RSC). They are just as strong for applications: we prove any application invariant that holds when using a strictly serializable (linearizable) service also holds when using an RSS (RSC) service. Yet they relax the constraints on services they allow new, better-performing designs. To demonstrate this, we design, implement, and evaluate variants of two systems, Spanner and Gryff, relaxing their consistency to RSS and RSC, respectively. The new variants achieve better read-only transaction and read tail latency than their counterparts.
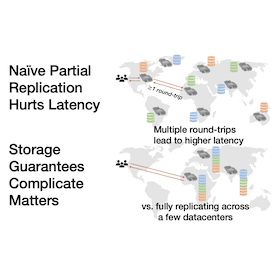
K2: Reading Quickly from Storage Across Many Datacenters
The infrastructure available to large-scale and medium-scale web services now spans dozens of geographically dispersed datacenters. Deploying across many datacenters has the potential to significantly reduce end-user latency by serving users nearer their location. However, deploying across many datacenters requires the backend storage system be partially replicated. In turn, this can sacrifice the low latency benefits of many datacenters, especially when a storage system provides guarantees on what operations will observe.
We present the K2 storage system that provides lower latency for large-scale and medium-scale web services using partial replication of data over many datacenters with strong guarantees: causal consistency, read-only transactions, and write-only transactions. K2 provides the best possible worst-case latency for partial replication, a single round trip to remote datacenters, and often avoids sending any requests to far away datacenters using a novel replication approach, write-only transaction algorithm, and read-only transaction algorithm.

Facebook’s Tectonic Filesystem: Efficiency from Exascale
Tectonic is Facebook’s exabyte-scale distributed filesystem. Tectonic consolidates large tenants that previously used service-specific systems into general multitenant filesystem instances that achieve performance comparable to the spe- cialized systems. The exabyte-scale consolidated instances enable better resource utilization, simpler services, and less operational complexity than our previous approach. This pa- per describes Tectonic's design, explaining how it achieves scalability, supports multitenancy, and allows tenants to specialize operations to optimize for diverse workloads. The paper also presents insights from designing, deploying, and operating Tectonic.
-

Paper
In FAST 2021
-

Video (Satadru Pan)
From FAST 2021
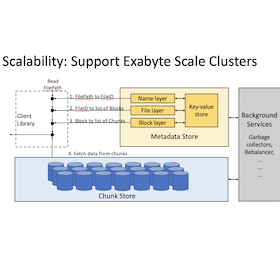
Tolerating Slowdowns in Replicated State Machines
using Copilots
Replicated state machines are linearizable, fault-tolerant groups of replicas that are coordinated using a consensus algorithm. Copilot replication is the first 1-slowdown-tolerant consensus protocol: it delivers normal latency despite the slowdown of any 1 replica. Copilot uses two distinguished replicas—the pilot and copilot—to proactively add redundancy to all stages of processing a client’s command. Copilot uses dependencies and deduplication to resolve potentially differing orderings proposed by the pilots. To avoid dependencies leading to either pilot being able to slow down the group, Copilot uses fast takeovers that allow a fast pilot to complete the ongoing work of a slow pilot. Copilot includes two optimizations—ping-pong batching and null dependency elimination—that improve its performance when there are 0 and 1 slow pilots respectively. Our evaluation of Copilot shows its performance is lower but competitive with Multi-Paxos and EPaxos when no replicas are slow. When a replica is slow, Copilot is the only protocol that avoids high latencies.
-

Paper
In OSDI 2020
-
Video (Khiem Ngo)
From OSDI 2020
-
Code
On GitHub
-

Tech Report
Pseudocode and Proof
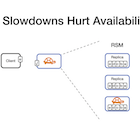
Performance-Optimal Read-Only Transactions
Read-only transactions are critical for consistently reading data spread across a distributed storage system but have worse performance than simple, non-transactional reads. We identify three properties of simple reads that are necessary for read-only transactions to be performance-optimal, i.e., come as close as possible to simple reads. We demonstrate a fundamental tradeoff in the design of read-only transactions by proving that performance optimality is impossible to achieve with strict serializability, the strongest consistency.
Guided by this result, we present PORT, a performance-optimal design with the strongest consistency to date. Central to PORT are version clocks, a specialized logical clock that concisely captures the necessary ordering constraints. We show the generality of PORT with two applications. Scylla-PORT provides process-ordered serializability with simple writes and shows performance comparable to its non-transactional base system. Eiger-PORT provides causal consistency with write transactions and significantly improves the performance of its transactional base system.
-

Paper
In OSDI 2020
-

Video (Haonan Lu)
From OSDI 2020
-
Scylla-PORT Code
On GitHub
-
Eiger-PORT Code
On GitHub
-

Tech Report
Extended Version
Learning Relaxed Belady
for Content Distribution Network Caching
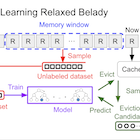
This paper presents a new approach for caching in CDNs that uses machine learning to approximate the Belady MIN (oracle) algorithm. To accomplish this complex task, we propose a CDN cache design called Learning Relaxed Belady (LRB) to mimic a Relaxed Belady algorithm, using the concept of Belady boundary. We also propose a metric called good decision ratio to help us make better design decisions. In addition, the paper addresses several challenges to build an end-to-end machine learning caching prototype, including how to gather training data, limit memory overhead, and have lightweight training and prediction.
We have implemented an LRB simulator and a prototype within Apache Traffic Server. Our simulation results with 6 production CDN traces show that LRB reduces WAN traffic compared to a typical production CDN cache design by 4–25%, and consistently outperform other state-of-the-art methods. Our evaluation of the LRB prototype shows its overhead is modest and it can be deployed on today’s CDN servers.
-

Paper
In NSDI 2020
-

Video (Zhenyu Song)
From NSDI 2020
-
Simulator Code
On GitHub
-
Prototype Code
On GitHub
Gryff: Unifying Consensus and Shared Registers
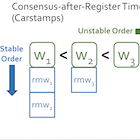
Linearizability reduces the complexity of building correct applications. However, there is a tradeoff between using linearizability for geo-replicated storage and low tail latency. Traditional approaches use consensus to implement linearizable replicated state machines, but consensus is inefficient for workloads composed mostly of reads and writes.
We present the design, implementation, and evaluation of Gryff, a system that offers linearizability and low tail latency by unifying consensus with shared registers. Gryff introduces carstamps to correctly order reads and writes without incurring unnecessary constraints that are required when ordering stronger synchronization primitives. Our evaluation shows that Gryff’s combination of an optimized shared register protocol with EPaxos allows it to provide lower service-level latency than EPaxos or MultiPaxos due to its much lower tail latency for reads.
-

Paper
In NSDI 2020
-

Video (Matthew Burke)
From NSDI 2020
-
Code
On GitHub
SVE: Distributed Video Processing at Facebook Scale
Videos are an increasingly utilized part of the experience of the billions of people that use Facebook. These videos must be uploaded and processed before they can be shared and downloaded. Uploading and processing videos at our scale, and across our many applications, brings three key requirements: low latency to support interactive applications; a flexible programming model for application developers that is simple to program, enables efficient processing, and improves reliability; and robustness to faults and overload. This paper describes the evolution from our initial monolithic encoding script (MES) system to our current Streaming Video Engine (SVE) that overcomes each of the challenges. SVE has been in production since the fall of 2015, provides lower latency than MES, supports many diverse video applications, and has proven to be reliable despite faults and overload.
-

Paper
In SOSP 2017
-
Video (Qi Huang)
From SOSP 2017
Popularity Prediction of Facebook Videos
for Higher Quality Streaming
with the Chess Video Prediction Service
Streaming video algorithms dynamically select between different versions of a video to deliver the highest quality version that can be viewed without buffering over the client’s connection. To improve the quality for viewers, the backing video service can generate more and/or better versions, but at a significant computational overhead. Processing all videos uploaded to Facebook in the most intensive way would require a prohibitively large cluster. Facebook’s video popularity distribution is highly skewed, however, with analysis on sampled videos showing 1% of them accounting for 83% of the total watch time by users. Thus, if we can predict the future popularity of videos, we can focus the intensive processing on those videos that improve the quality of the most watch time.
To address this challenge, we designed Chess, the first popularity prediction algorithm that is both scalable and accurate. Chess is scalable because, unlike the state-of-the-art approaches, it requires only constant space per video, enabling it to handle Facebook’s video workload. Chess is accurate because it delivers superior predictions using a combination of historical access patterns with social signals in a unified online learning framework. We have built a video prediction service, ChessVPS, using our new algorithm that can handle Facebook’s workload with only four machines. We find that re-encoding popular videos predicted by ChessVPS enables a higher percentage of total user watch time to benefit from intensive encoding, with less overhead than a recent production heuristic, e.g., 80% of watch time with one-third as much overhead.
-

Paper
In ATC 2017
-

Audio (Linpeng Tang)
From ATC 2017

I Can’t Believe It’s Not Causal!
Scalable Causal Consistency with No Slowdown Cascades
We describe the design, implementation, and evaluation of Occult (Observable Causal Consistency Using Lossy Timestamps), the first scalable, geo-replicated data store that provides causal consistency to its clients without exposing the system to the possibility of slowdown cascades, a key obstacle to the deployment of causal consistency at scale. Occult supports read/write transactions under PC-PSI, a variant of Parallel Snapshot Isolation that contributes to Occult’s immunity to slowdown cascades by weakening how PSI replicates transactions committed at the same replica. While PSI insists that they all be totally ordered, PC-PSI simply requires total order Per Client session. Nonetheless, Occult guarantees that all transactions read from a causally consistent snapshot of the datastore without requiring any coordination in how transactions are asynchronously replicated.
-

Paper
From NSDI 2017
-

Video (Akbar Mehdi)
From NSDI 2017

The SNOW Theorem
and Latency-Optimal Read-Only Transactions
Scalable storage systems where data is sharded across many machines are now the norm for Web services as their data has grown beyond what a single machine can handle. Consistently reading data across different shards requires transactional isolation for the reads. Yet a Web service may read from its data store hundreds or thousands of times for a single page load and must minimize read latency to keep response times low. Examining the read-only transaction algorithms for many recent academic and industrial scalable storage systems suggests there is a tradeoff between their power—expressed as the consistency they provide and their compatibility with other types of transactions—and their latency.
We show that this tradeoff is fundamental by proving the SNOW Theorem, an impossibility result that states that no read-only transaction algorithm can provide both the lowest latency and the highest power. We then use the tight boundary from the theorem to guide the design of new read-only transaction algorithms for two scalable storage systems, COPS and Rococo. We implement our new algorithms and then evaluate them to demonstrate they provide lower latency for read-only transactions and to understand their impact on overall throughput.
-

Paper
From OSDI 2016
-

Audio (Haonan Lu)
From OSDI 2016
-
COPS-SNOW Code
On GitHub
-
Rococo-SNOW Code
On GitHub

Consolidating Concurrency Control and Consensus
for Commits under Conflicts with Janus
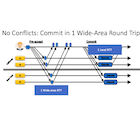
Conventional fault-tolerant distributed transactions layer a traditional concurrency control protocol on top of the Paxos consensus protocol. This approach provides scalability, availability, and strong consistency. When used for wide-area storage, however, this approach incurs cross-data-center coordination twice, in serial: once for concurrency control, and then once for consensus. In this paper, we make the key observation that the coordination required for concurrency control and consensus is highly similar. Specifically, each tries to ensure the serialization graph of transactions is acyclic. We exploit this insight in the design of Janus, a unified concurrency control and consensus protocol.
Janus targets one-shot transactions written as stored procedures, a common, but restricted, class of transactions. Janus can commit unconflicted transactions in this class in one round-trip and avoids aborts due to contention: it commits conflicted transactions in this class in at most two round-trips as long as the network is well behaved and a majority of each server replica is alive. We compare Janus with layered designs and TAPIR under a variety of workloads in this class. Our evaluation shows that Janus achieves 5× the throughput of a layered system and 90% of the throughput of TAPIR under a contention-free microbenchmark. When the workloads become contended, Janus provides much lower latency and higher throughput (up to 6.8×) than the baselines.
-

Paper
From OSDI 2016
-

Audio (Shuai Mu)
From OSDI 2016
-
Code
On GitHub
Existential Consistency:
Measuring and Understanding Consistency at Facebook
Replicated storage for large Web services faces a trade-off between stronger forms of consistency and higher performance properties. Stronger consistency prevents anomalies, i.e., unexpected behavior visible to users, and reduces programming complexity. There is much recent work on improving the performance properties of systems with stronger consistency, yet the flip-side of this trade-off remains elusively hard to quantify. To the best of our knowledge, no prior work does so for a large, production Web service.
We use measurement and analysis of requests to Facebook's TAO system to quantify how often anomalies happen in practice, i.e., when results returned by eventually consistent TAO differ from what is allowed by stronger consistency models. For instance, our analysis shows that 0.0004% of reads to vertices would return different results in a linearizable system. This in turn gives insight into the benefits of stronger consistency; 0.0004% of reads are potential anomalies that a linearizable system would prevent. We directly study local consistency models—i.e., those we can analyze using requests to a sample of objects—and use the relationships between models to infer bounds on the others.
We also describe a practical consistency monitoring system that tracks φ-consistency, a new consistency metric ideally suited for health monitoring. In addition, we give insight into the increased programming complexity of weaker consistency by discussing bugs our monitoring uncovered, and anti-patterns we teach developers to avoid.
-

Paper
From SOSP 2015
-

Slides
From SOSP 2015
-
Video (Haonan Lu)
From SOSP 2015
RIPQ: Advanced Photo Caching on Flash for Facebook
Facebook uses flash devices extensively in its photo- caching stack. The key design challenge for an efficient photo cache on flash at Facebook is its workload: many small random writes are generated by inserting cache- missed content, or updating cache-hit content for advanced caching algorithms. The Flash Translation Layer on flash devices performs poorly with such a workload, lowering throughput and decreasing device lifespan. Existing coping strategies under-utilize the space on flash devices, sacrificing cache capacity, or are limited to simple caching algorithms like FIFO, sacrificing hit ratios.
We overcome these limitations with the novel Restricted Insertion Priority Queue (RIPQ) framework that supports advanced caching algorithms with large cache sizes, high throughput, and long device lifespan. RIPQ aggregates small random writes, co-locates similarly prioritized content, and lazily moves updated content to further reduce device overhead. We show that two families of advanced caching algorithms, Segmented-LRU and Greedy-Dual-Size-Frequency, can be easily implemented with RIPQ. Our evaluation on Facebook’s photo trace shows that these algorithms running on RIPQ increase hit ratios up to ~20% over the current FIFO system, incur low overhead, and achieve high throughput.
-

Paper
From FAST 2015
-

Slides
From FAST 2015
-

Video (Linpeng Tang)
From FAST 2015
-

Theoretical Analysis
From Jan 2015
-

FB Research Blog Post
From Apr 2016
Extracting More Concurrency from Distributed Transactions
with Rococo
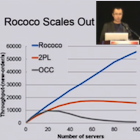
Distributed storage systems run transactions across machines to ensure serializability. Traditional protocols for distributed transactions are based on two-phase locking (2PL) or optimistic concurrency control (OCC). 2PL serializes transactions as soon as they conflict and OCC resorts to aborts, leaving many opportunities for concurrency on the table. This paper presents Rococo, a novel concurrency control protocol for distributed transactions that outperforms 2PL and OCC by allowing more concurrency. Rococo executes a transaction as a collection of atomic pieces, each of which commonly involves only a single server. Servers first track dependencies between concurrent transactions without actually executing them. At commit time, a transaction’s dependency information is sent to all servers so they can re-order conflicting pieces and execute them in a serializable order.
We compare Rococo to OCC and 2PL using a scaled TPC-C benchmark. Rococo outperforms 2PL and OCC in workloads with varying degrees of contention. When the contention is high, Rococo’s throughput is 130% and 347% higher than that of 2PL and OCC.
-

Paper
From OSDI 2014
-

Slides
From OSDI 2014
-
Video (Shuai Mu)
From OSDI 2014
-
Code
On GitHub
f4: Facebook’s Warm BLOB Storage System
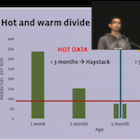
Facebook’s corpus of photos, videos, and other Binary Large OBjects (BLOBs) that need to be reliably stored and quickly accessible is massive and continues to grow. As the footprint of BLOBs increases, storing them in our traditional storage system, Haystack, is becoming increasingly inefficient. To increase our storage efficiency, measured in the effective-replication-factor of BLOBs, we examine the underlying access patterns of BLOBs and identify temperature zones that include hot BLOBs that are accessed frequently and warm BLOBs that are accessed far less often. Our overall BLOB storage system is designed to isolate warm BLOBs and enable us to use a specialized warm BLOB storage system, f4. f4 is a new system that lowers the effective-replication-factor of warm BLOBs while remaining fault tolerant and able to support the lower throughput demands.
f4 currently stores over 65PBs of logical BLOBs and reduces their effective-replication-factor from 3.6 to either 2.8 or 2.1. f4 provides low latency; is resilient to disk, host, rack, and datacenter failures; and provides sufficient throughput for warm BLOBs.
-

Paper
From OSDI 2014
-

Slides
From OSDI 2014
-
Video (Sabyasachi Roy)
From OSDI 2014
An Analysis of Facebook Photo Caching
This paper examines the workload of Facebook's photo-serving stack and the effectiveness of the many layers of caching it employs. Facebook’s image-management infrastructure is complex and geographically distributed. It includes browser caches on end-user systems, Edge Caches at ~20 PoPs, an Origin Cache, and for some kinds of images, additional caching via Akamai. The underlying image storage layer is widely distributed, and includes multiple data centers.
We instrumented every Facebook-controlled layer of the stack and sampled the resulting event stream to obtain traces covering over 77 million requests for more than 1 million unique photos. This permits us to study traffic patterns, cache access patterns, geolocation of clients and servers, and to explore correlation between properties of the content and accesses. Our results (1) quantify the overall traffic percentages served by different layers: 65.5% browser cache, 20.0% Edge Cache, 4.6% Origin Cache, and 9.9% Backend storage, (2) reveal that a significant portion of photo requests are routed to remote PoPs and data centers as a consequence both of load-balancing and peering policy, (3) demonstrate the potential performance benefits of coordinating Edge Caches and adopting S4LRU eviction algorithms at both Edge and Origin layers, and (4) show that the popularity of photos is highly dependent on content age and conditionally dependent on the social-networking metrics we considered.
-

Paper
From SOSP 2013
-

Slides
From SOSP 2013
-

Video (Qi Huang)
From SOSP 2013
-

FB Eng Blog Post
From Feb 2014
Stronger Semantics for Low-Latency Geo-Replicated Storage
with Eiger
We present the first scalable, geo-replicated storage system that guarantees low latency, offers a rich data model, and provides "stronger" semantics. Namely, all client requests are satisfied in the local datacenter in which they arise; the system efficiently supports useful data model abstractions such as column families and counter columns; and clients can access data in a causally-consistent fashion with read-only and write-only transactional support, even for keys spread across many servers.
The primary contributions of this work are enabling scalable causal consistency for the complex column-family data model, as well as novel, non-blocking algorithms for both read-only and write-only transactions. Our evaluation shows that our system, Eiger, achieves low latency (single-ms), has throughput competitive with eventually-consistent and non-transactional Cassandra (less than 7% overhead for one of Facebook's real-world workloads), and scales out to large clusters almost linearly (averaging 96% increases up to 128 server clusters).
-

Paper
From NSDI 2013
-

Slides
From NSDI 2013
-

Video
From NSDI 2013
-
Code
On GitHub
Don’t Settle for Eventual:
Causal Consistency for Wide-Area Storage with COPS
Geo-replicated, distributed data stores that support complex online applications, such as social networks, must provide an "always-on" experience where operations always complete with low latency. Today's systems often sacrifice strong consistency to achieve these goals, exposing inconsistencies to their clients and necessitating complex application logic. In this paper, we identify and define a consistency model--causal consistency with convergent conflict handling, or causal+--that is the strongest achieved under these constraints.
We present the design and implementation of COPS, a key-value store that delivers this consistency model across the wide-area. A key contribution of COPS is its scalability, which can enforce causal dependencies between keys stored across an entire cluster, rather than a single server like previous systems. The central approach in COPS is tracking and explicitly checking whether causal dependencies between keys are satisfied in the local cluster before exposing writes. Further, in COPS-GT, we introduce get transactions in order to obtain a consistent view of multiple keys without locking or blocking. Our evaluation shows that COPS completes operations in less than a millisecond, provides throughput similar to previous systems when using one server per cluster, and scales well as we increase the number of servers in each cluster. It also shows that COPS-GT provides similar latency, throughput, and scaling to COPS for common workloads.
-

Paper
From SOSP 2011
-

Slides
From SOSP 2011
-

Video
From SOSP 2011
Low-Overhead Transparent Recovery for Static Content
with TRODS
Client connections to web services break when the particular server they are connected to fails or is taken down for maintenance. We designed and built TRODS, a system that transparently recovers connections to web services that delivers static content, e.g., photos or videos. TRODS is implemented as a server-side kernel module for immediate deployability, it works with unmodified services and clients. The key insight in TRODS is its use of cross-layer visibility and control: It derives reliable storage for application-level state from the mechanics of the transport layer. In contrast with more general recovery techniques, the overhead of TRODS is minimal. It provides throughput-per-server competitive with unmodified HTTP services, enabling recovery without additional capital expenditures.
-

Paper
From DSN 2011
-

Slides
From DSN 2011
Using History for High-Throughput Fault Tolerance
with Prophecy
Byzantine fault-tolerant (BFT) replication provides protection against arbitrary and malicious faults, but its performance does not scale with cluster size. We designed and built Prophecy, a system that interposes itself between clients and any replicated service to scale throughput for read-mostly workloads. Prophecy relaxes consistency to delay-once linearizability so it can perform fast, load-balanced reads when results are historically consistent, and slow, replicated reads otherwise. This dramatically increases the throughput of replicated services, e.g., the throughput of a 4 node Prophecy web service is ~4X the throughput of a 4 node PBFT web service.
-

Paper
From NSDI 2010
IP Address Passing for VANETs
In Vehicular Ad-hoc Networks (VANETs), vehicles have short connection times when moving past wireless access points. The time required for acquiring IP addresses via DHCP consumes a significant portion of each connection. We reduce the connection time to under a tenth of a second by passing IP addresses between vehicles. Our implementation improves efficiency, reduces latency, and increases vehicle connectivity without modifying either DHCP or AP software.
-

Paper
From PerComm 2008