NOTE: Since the due date of this assignment is Dean's date, no late days will be accepted for this homework.
The written exercises are available here in pdf format.
Be sure to show your work and justify all of your answers.
In this assignment, you will implement some of the algorithms for computing policies in Markov decision processes (MDPs). The policies will help a mouse avoid a cat while finding cheese to eat.
The main components of the assignment are the following:
The first parts of the assignment is to implement four of the algorithms that were discussed in lecture as well as R&N (sections 17.2, 17.3, and 21.3): value iteration, policy iteration, policy evaluation, and Q-learning agent. Your implementations should work for any (reasonable) MDP, not just the ones provided. See below for a description of where you should write your code.
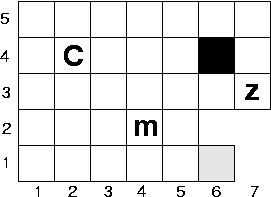
The last part of the assignment is to use your code to compute optimal policies for a mouse who lives with a cat in the following grid world:
The mouse (m) can occupy any of the 31 blank squares. The cat (C) also can occupy any square, except for square (6,1) which is the mouse's hole (too small for the cat to squeeze in). There is cheese (z) that, at any given time, can be found in one of the following four squares: (2,3), (4,1), (5,5) and (7,3). Thus, this MDP has 31*30*4=3720 states.
The cat and the mouse can each move one square in any direction -- vertically, horizontally or diagonally. They also can choose not to move at all. Thus, there are nine possible moves from each square. If an action is attempted that causes the creature to bump into a wall, then it simply stays where it is.
In this problem, we will always take the point of view of the mouse. When the mouse is on the cheese, it receives a reward of 1. When the cat is on the mouse, it (the mouse) receives a reward of -11. When the cat is on the mouse and the mouse is on the cheese, it receives a reward of -10. All other configurations have a reward of 0. Thus, the mouse is trying to eat the cheese while simultaneously avoiding the cat.
We will consider three different cats. The first cat, poor thing, is blind and oblivious, and simply wanders randomly around its environment choosing randomly among its nine available actions at every step. The second cat is hungry, alert and unrelenting. This cat always heads straight for the mouse following the shortest path possible. Thus, after the mouse makes its move, the cat chooses the action that will move it as close as possible to the mouse's new position. (If there is a tie among the cat's best available options, the cat chooses randomly among these equally good best actions.) However, when the mouse is in its hole and out of sight, the cat reverts to aimless (i.e., random) wandering. The third cat is also alert, but has a more sporting disposition, and therefore follows a combination of these two strategies: half the time, it wanders aimlessly, and half the time, it heads straight for the mouse. Machine-readable (and compressed) descriptions of the three MDPs corresponding to these three cats is provided in the files oblivious.mdp.gz, unrelenting.mdp.gz and sporting.mdp.gz.
There is always cheese available in exactly one of the four locations listed above. At every time step, the cheese remains where it is with 90% probability. With 10% probability, the cheese vanishes and reappears at one of the four locations, chosen randomly.
States are encoded as six tuples, the first two numbers indicating the position of the mouse, the second two numbers the position of the cat, and the last two numbers the position of the cheese. Thus, 4:2:2:4:7:3 indicates, as depicted in the figure above, that the mouse is in (4,2), the cat is in (2,4), and the cheese is in (7,3). The cat and the mouse alternate moves. However, in encoding the MDP, we collapse both moves into a single state transition. In addition, the cheese, when it moves, does so simultaneously with the mouse's move. For instance, from the configuration above, if the mouse moves to (5,2) and the cat responds by moving to (3,3), while the cheese moves to (5,5), this all would be encoded as a single transition from state 4:2:2:4:7:3 to 5:2:3:3:5:5. Actions in the MDP refer to action's that the mouse can make; the cat's actions are effectively "hard-wired" into the dynamics of the MDP itself.
For each of the three cats, your job will be to compute the mouse's (optimal) policy, i.e., the action that should be taken at each state to maximize the mouse's expected discounted reward, where we fix the discount factor (gamma) to be 0.95. You can then watch the cat and the mouse go at it using an animator that we are providing.
Once you have the value iteration, policy iteration, and policy evaluation algorithms working, you should take some time to understand the mouse's behavior in each of the three cases. Then briefly write up your observations in 2-4 paragraphs (all together, not per case). As on HW#5, you can make observations that are either anecdotal or quantitative or both. Think about questions like the following suggestions: How is the mouse behaving in each case and why does this behavior make sense? What sorts of intelligent behavior appear to be emerging? Is the behavior what you would have expected, or are there aspects of the mouse's behavior that you found surprising? What happens if you take the mouse's optimal policy for cat A and have the mouse follow that policy when playing against cat B? Since there are three cats, there are nine possibilities here. Construct a matrix showing the utility (say, averaged over all possible starting states), for all nine possibilities. Which policy should the mouse follow if it doesn't know which cat it's up against? Why? You may also wish to explore the performance of the algorithms themselves. For instance, how many iterations does it take to reach convergence? How is performance affected if we stop iterating one of the algorithms before we reach convergence? What happens if we vary gamma?
Once you have the Q-learning agent algorithm working, you will be free to explore how the agent's behavior varies according to various parameters:
Please write your observations resulting from these explorations in 2-4 paragraphs. For example, you may want to construct a matrix showing the utility (again, averaged over all possible starting states) for each possible assignment of the aforementioned parameters. Which combination of parameters works best? Why? When doing such an evaluation, you will most likely want to measure how well the Q-learning agent's policy conforms with that of the optimal policy (say the one returned by policy iteration). You will also want to observe how quickly the Q-learning agent's policy converges. How well does the Q-learning agent do after 10,000 iterations? 1,000,000 iterations? 100,000,000 iterations?
We are providing a class called Mdp that loads a description of an MDP from a file whose format is described shortly. The class has a constructor taking a file name as argument that reads in the MDP description from the file. Each state is represented by an integer in the range 0 (inclusive) to numStates (exclusive), where numStates is the total number of states. Actions are represented in a similar fashion. The stateName and actionName arrays convert these integers back to strings in the obvious fashion. The reward array gives the immediate reward of each state. For efficiency, state transition probabilities are represented in a sparse fashion to take advantage of the fact that most states have a relatively small number of possible successors. In particular, the array nextState[s][a] represents a list of possible next states which may follow state s under action a. The understanding here is that the probability of transitioning to any other state is zero. There is a corresponding list of probabilities transProb[s][a]. Thus, transProb[s][a][i] is the probability of transitioning from s to nextState[s][a][i] under action a.
Each line of an MDP description file has one of three possible formats. The first possibility is that the line has the simple form
<state>
where <state> is any name (no white space). Such a line indicates that <state> is the start state of the MDP.
The second possibility is that the line has the form
<state> <reward>
where <state> is any name, and <reward> is a number. Such a line indicates that the reward in <state> is <reward>.
The last possibility is that the line has the form
<from_state> <action> <to_state> <prob>
where the first three tokens are names, and <prob> is a nonnegative number. Such a line indicates that the probability of transitioning from <from_state> to <to_state> under action <action> is <prob>. Multiple lines of this form with the same <from_state> and <action> can be combined. Thus,
u a v 0.3 u 0.4 w 0.1
is equivalent to the three lines
u a v 0.3
u a u 0.4
u a w 0.1
Lines of these forms can appear in the file in any order. However, if a reward is given more than once for the same state, then the last reward value given is assigned to that state. On the other hand, if more than one probability is given for the same state-action-state triple, then the sum of these probabilities is assigned to this transition. If the probabilities of transitioning out of a given state under a given action do not add up to one, then these numbers are renormalized so that they do. However, if this sum is zero, an exception is thrown. States that are not given a reward in the description file are assumed to have a reward of zero; likewise, transitions that do not appear in the file are assumed to have zero probability. An exception is also thrown if no start state is declared (using the first form above); if more than one such line appears, then the last one is taken to define the start state.
For instance, the following encodes an MDP with five states, -2, -1, 0, +1 and +2. There are two actions, L(eft) and R(ight) which cause the MDP to move to the next state to the left or right 90% of the time, or to move in the opposite direction 10% of the time (with movement impeded at the end points -2 and +2). The start state is 0. The reward is 1 in 0, -1 in -2, and -2 in +2. The start state is 0.
0
0 1
0 L -1 0.9 +1 0.1
0 R +1 0.9 -1 0.1
-1 L -2 0.9 0 0.1
-1 R 0 0.9 -2 0.1
-2 -1
-2 L -2 0.9 -1 0.1
-2 R -1 0.9 -2 0.1
+1 R +2 0.9 0 0.1
+1 L 0 0.9 +2 0.1
+2 -2
+2 R +2 0.9 +1 0.1
+2 L +1 0.9 +2 0.1
If you want to try out or test your program on MDPs of your own invention (which is highly recommended), you can do so by creating files of this form. Alternatively, you can create a subclass of the Mdp class, and write code that fills in the public fields with a description of your MDP.
Because the files being provided for the cat and mouse MDPs are quite large, we are providing them in a compressed (gzipped) form. Note that the Mdp class will automatically read a file that has been gzipped, provided that it ends with a ".gz" suffix. In other words, there is no need to uncompress the gzipped files that we are providing prior to running your code on them. (Of course, the code will also work on files that have not been compressed.) In addition, because these MDPs are somewhat large, you may need to increase the memory available to java (the option for doing this is system dependent, but it often has the form -Xmx256m which increases the memory to 256 megabytes).
The class CatMouseAnimator can be used to animate a given policy on one of the cat-and-mouse MDPs. The method animateGuiOnly invokes a graphical user interface (GUI) for this purpose showing the behavior of the cat and mouse in a graphical depiction of their grid-world, similar to the one above. Buttons are provided for starting or stopping the animation (at a speed that can be controlled), or for stepping through the animation one step at a time.
The method animateGuiAndPrint invokes the GUI as well, but also prints the state of the MDP at every step. The printed form of each state looks something like the following:
+===============+
| . . . . . . . |
| . C . . . . |
| . . . . . . z |
| . . . m . |
| . . . . . _ |
+===============+
As in the GUI, the letters m, C and z indicate the position of the mouse, cat and cheese. The mouse's hole is indicated with an underscore. In both the printed and GUI depictions, the mouse vanishes when the cat is on top of it; likewise, the cheese can be obscured by either the cat or the mouse (although the mouse changes from lower to upper case M when it is eating).
A final method animatePrintOnly prints the successive states of the MDP under the given policy, but does not invoke the GUI.
The class RunCatMouse consists only of a main that loads an MDP from a file, finds and prints the (optimal) policy (using the algorithms specified by the command line arguments) and runs the animator (depending on command line arguments -- see the documentation). The command line arguments used to specify which algorithm(s) to run are:
The policy used by the animator will be the result of the last algorithm according to the order above. For example, if the program is invoked with the options -pi -q 1000000 then the q-learning agent's policy will be used for the animator. But if the program is invoked with -pi -vi, then the result of policy iteration will be used as the animator's policy.
Before starting the animator, columns are printed following each state: the first set of columns are the policies returned by the algorithms specified on the command line. The second set of columns are the corresponding estimated utilities. The columns are sorted according the order above. For instance, on the simple five-state MDP given above, invoked with -pi -vi, the output should look something like this:
Optimal policies:
0 L L 8.169018052871904 8.169018052871904
-1 R R 7.5578670677920545 7.5578670677920545
+1 L L 7.442544315827016 7.442544315827016
-2 R R 6.035332975545492 6.035332975545492
+2 L L 4.821409270650342 4.821409270650342
In this case, the first column following the state is the optimal policy found through value iteration, and the second column is the optimal policy found through policy iteration. The third column is the estimated utility using value iteration. Finally, the fourth column is the estimated utility of the optimal policy using policy evaluation.
In this case, as expected, the optimal policy says to move to the center (right if in -1 or -2, and left if in +1 or +2), and to move left (away from the larger penalty state +2) if in the center.
You might well decide to modify or replace the RunCatMouse class. However, your code should still work properly when run using the provided version.
To debug your code, you will surely want to run it on small MDPs. There are a number of "sanity checks" that can be done to see if your code is working. For instance, value iteration and policy iteration should output identical policies (up to possible ties between equally good actions). In addition, the utility of the optimal policy must satisfy the Bellman equations.
All code and data files can be obtained from this directory, or all at once from this zip file. Data is included in the data subdirectory. The provided code should work with Java 1.5.0.
Documentation on the provided Java classes is available here.
You will need to fill in the constructors in the three classes ValueIteration, PolicyIteration and PolicyEvaluation. The constructor for ValueIteration takes as input an MDP and a discount factor; the constructed class then includes a field policy containing the optimal policy (an array mapping states to actions), and another field utility (an array mapping states to real numbers). The other two classes are set up similarly. You may wish to add other fields that are returned as part of the class, such as the number of iterations until convergence.
You will also need to fill in the QLearningAgent class. The QLearningAgent's constructor will be passed some basic parameters of the environment. In addition, you will need to fill in the doStep method which will be called to report the reward of the previous action and which should return the next action to take. The doStep method should call the explorationFunction, which you should also fill in. The constructed class contains a field Q containing the Q-values for each action-state pair, and N containing the frequency of each state-action pair. There are also two other methods you must fill in: getUtility and getPolicy which should return arrays corresponding to the similarly designated fields in the other classes. Again, you may add any other fields or methods you find helpful.
The final code that you turn in should not write anything to standard output or standard error. Your code must work properly when run with the provided classes on the provided MDPs.
Using moodle, you should turn in the following:
In addition, you should turn in your write-up exploring the cat-and-mouse environments as described above. This written work should be handed in with the written exercises.
We will automatically test your code on MDPs other than those provided with this assignment. Your grade will depend largely on getting the right answers. In addition, your code should be efficient enough to run reasonably fast (under a minute or two on a fast machine on an MDP like those provided), and should not terminate prematurely with an exception (unless given bad data, of course); code that does otherwise risks getting no credit for the automatic testing portion of the grade. As usual, you should follow good programming practices, including documenting your code.
Your write-up should be clear, concise, thoughtful and perceptive.
Thanks to Dale Schuurmans from whom the main idea for this assignment was borrowed.