Using LESS Data to Tune Models
Data Selection in the Era of LLMs
TL;DR: We describe how data selection for modern-day LLMs differs from prior settings and how our algorithm, LESS, effectively selects relevant data to cultivate specific capabilities in models during instruction tuning.
Paper: https://arxiv.org/abs/2402.04333
Code: https://github.com/princeton-nlp/LESS/
This post will take the following structure:
- We introduce the motivation for data selection and describe how the criteria for “good” data depends heavily on the setting. One can either try to identify representative datapoints for the in-domain setting or relevant ones for the transfer setting.
- Our algorithm, LESS, effectively selects relevant data to induce capabilities in the instruction tuning setting. LESS identifies 5% of the dataset that induces stronger performance than training on the full dataset.
- We conduct an in-depth analysis of prior works on data selection for various settings and provide insights into their technical details, strengths, and limitations.
- We conclude by identifying trends in data selection in the era of LLMs.
Motivation
The training dataset is a crucial design choice when building a machine learning model. Dataset choice can drive the capabilities of the resulting model in various ways (see, for example, CodeLLaMA, and DeepSeek-Math). Also, training models can be expensive, and the cost usually scales with the size of the dataset, so dataset selection offers one way to improve efficiency and reduce cost.

Transfer data selection selects the subset that is closest to the target data points.
We distinguish two settings for data selection: in-domain data selection and transfer data selection. In the former, the selected data is drawn from the same distribution as the evaluation data1 , whereas in the latter, evaluation is performed on different data.
- In-domain data selection aims to identify the most representative subset of data, often referred to as a coreset (Sener & Severese 2018), from a large in-domain training dataset. The selection criteria include representativeness, coverage, correctness, and more. We talk more about this setting latter.
- Transfer data selection seeks to choose the most relevant data from a broad training pool that closely align with the target examples. The selection criterion focuses on relevancy.
Our work focuses on transfer data selection for instruction tuning. Instruction tuning has proven to be a highly effective way to quickly adapt language models to follow human instructions. Depending on the data used, models can be tuned to be general-purpose instruction followers (e.g., Alpaca, Vicuna, Zephyr) or solve more structured tasks per human instructions (i.e., targeted instruction tuning). Our work focuses on selecting data for the latter case, where models are tuned to perform particular types of reasoning (e.g., using a passage to answer a question). In this case, the data selection problem can be understood as bootstrapping a few examples to identify relevant data to solve a task.
Selecting LESS Datapoints for Targeted Instruction Tuning
The targeted instruction tuning setting poses the following research question:
Several data selection strategies have been developed for pre-training, such as continued training on domain-specific data (Gururangan et al., 2020) and using n-gram statistics to identify relevant data (Xie et al., 2023). However, the instruction tuning setting is unique in that using all of the available data can hurt the development of specific capabilities (Wang et al., 2023), and one wants to somehow account for the properties of the pre-trained model when selecting data. So, we avoid using heuristic definitions of useful data and instead frame data selection as a rigorous optimization problem. As we describe in the next section, LESS selects training data to minimize the loss on the target data (i.e., the few handwritten validation examples). Check out our paper here and play with the code on GitHub!
Conceptual Approach
Suppose we have a handwritten validation example $z$ and a huge dataset of candidate training points $\mathcal{D}$. At the heart of any transfer data selection algorithm is the same question: how does training on some point $x\in\mathcal{D}$ affect the model’s performance on $z$? We explicitly formulate this by approximating how the validation loss $\ell(z;\theta)$ changes when we take one training step (i.e., update the model from $\theta_t$ to $\theta_{t+1}$) on a candidate datapoint $x$:
Assume that we were training with SGD with step size $\eta_t$, we can further derive the following formulation:
We can see that selecting $x$ to maximize $\langle \nabla \ell (z;\theta_t), \nabla \ell (x;\theta_t)\rangle$ will maximally reduce the validation loss on $z$. The method was initially proposed and employed in TracIn (Pruthi et al., 2020) to gain insights into how training examples influence the model’s predictions. The formulation is also very suitable for transfer learning, because there is no need to assume any relationship between $x$ and $z$. But, there are a couple of modifications required to make it work for our setting (see our paper for details):
- Adam: LLMs are generally tuned using Adam, which has a more complicated update formula involving the moving averages of the gradient moments. We can plug in that update, which we denote as $\Gamma(x;\theta_t)$ instead of $\nabla\ell(x;\theta_t)$. See the paper for details on the Adam formulation and the resulting technical complications.
- Multi-Epoch: We usually train our models over several epochs, which means each candidate $x\in\mathcal{D}$ would be seen several times over the course of training. We would want our estimate of the influence of $x$ to take this into account, but we want to avoid the computational cost of training on the entire candidate dataset for several epochs. Instead, we approximate how the model would adapt to seeing the same data by performing a warmup training period on a randomly selected 5% of the data and aggregating the influence over the whole run. See the paper for how we aggregate influences over multiple epochs.
- Variable-Length Instruction Data: Instruction tuning sequences have differing lengths. Experiments in our paper showed that shorter sequences exhibit much larger norms, so the inner product $\langle \nabla \ell (z;\theta_t), \nabla \ell (x;\theta_t)\rangle$ is much larger for shorter $x$. We therefore decide to instead use the cosine similarity instead of the inner product when measuring the influence. This is not a failure of the formulation described above (which indeed is quite simple); instead, it indicates that we ought to perform data selection for individual tokens instead of entire sequences. However, measuring the gradient of every token in the sequence is prohibitively expensive with today’s methods, so we stick to sequence selection and leave a token-level formulation to future work.
Altogether, once we make the necessary modifications, we arrive at the following formula for computing the influence of a training datapoint $x$ on a validation point $z$.
where $\Gamma(x; \theta_i)$ is the Adam update mentioned above, $N$ is the number of epochs during warmup training (see next section), $\bar\eta_i$ is the average learning rate in the $i$th epoch, and $\theta_i$ is the model after the $i$th epoch. The above formula makes it clear that we need to handle model gradient vectors, which can be very large, and we need to aggregate influences over several model checkpoints. In the next section, we describe how we compute this formula efficiently.
Selecting LESS Data

LESS consists of four major steps to make influence estimation feasible and scalable:
- Warmup LoRA training: We train the model with a warmup phase with a random subset of data and checkpoint the model $\theta_i$ and optimizer update $\Gamma$ over $N$ epochs. We choose to train with LoRA to operate on gradients in a much smaller space (i.e., ~100M parameters for a 7B model).
- Compute gradient features: We acquire low-rank Adam gradients by further projecting the LoRA gradients down to a smaller dimension $d$ (i.e., 8192 in our experiments).2
- Select data: Given a few instances from target tasks, we first acquire their compressed gradients. We then calculate the influence $\mathrm{Inf}$ and pick the examples with the highest scores.3
- Train models: We train models on the selected data, using either full-parameter fine-tuning or efficient fine-tuning approaches like LoRA.
Note that the first and second steps are computed once per candidate training set and can be stored as a gradient datastore. The datastore can be reused to quickly select data for different validation tasks. Moreover, the model used to select data in steps 1-3 can be different from the model trained in step 4, and we call this setting LESS-T, where “T” stands for transfer.
Results
Training on 5% selected data often outperforms training on the full dataset
We construct our dataset pool to be a combination of subsets FLAN V2, COT, Open Assistant 1, and Dolly datasets. On Mistral-7B and Llama-2-13B, we find that the selected 5% of the data outperforms using the full dataset. Additionally, we find that the data selected with Llama-2-7B is also effective for instruction-tuning Llama-2-13B and Mistral-7B (LESS-T).



LESS-T indicates that we used LLaMA-2-7B to select the data for training the model.
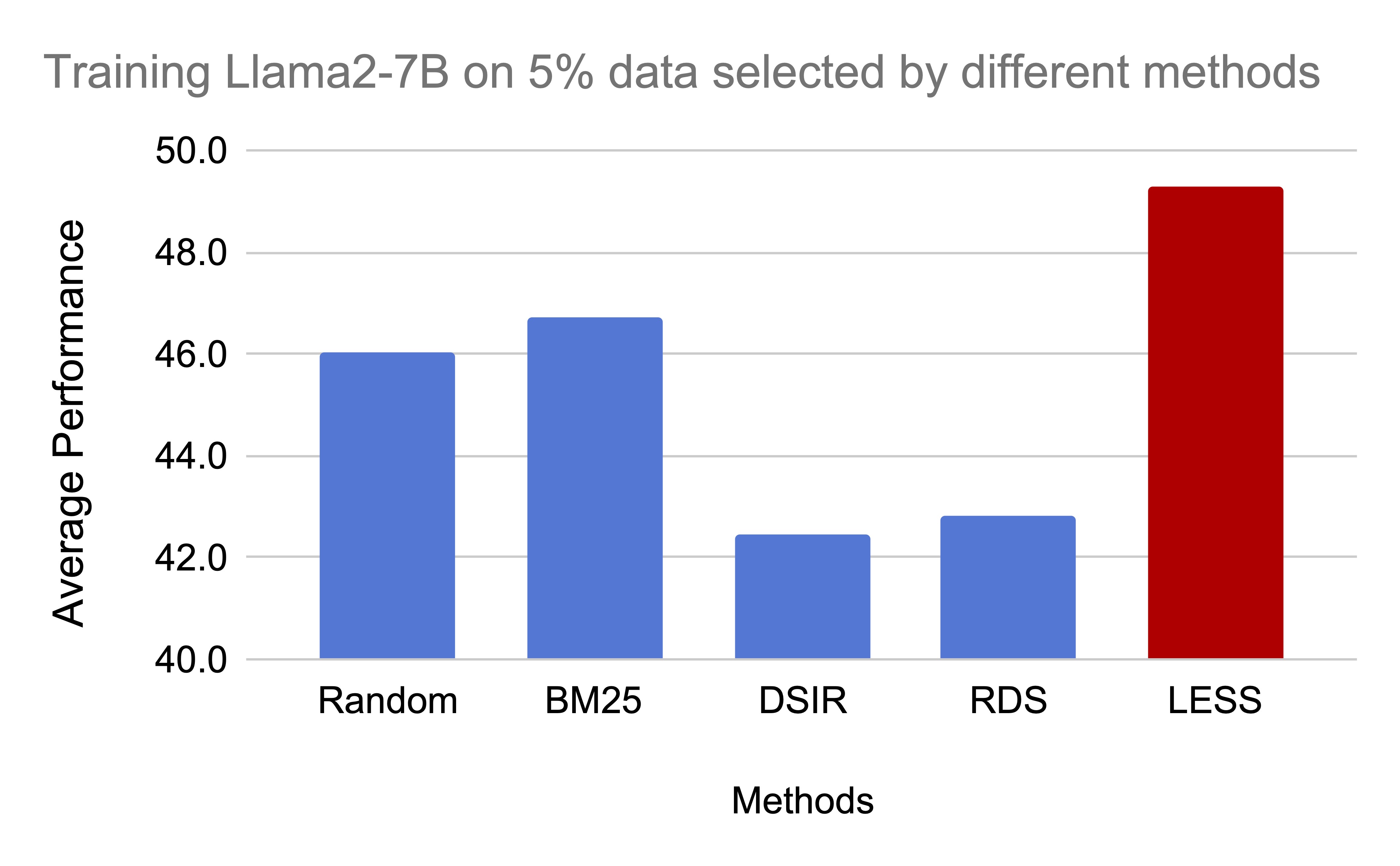
LESS outperforms the baselines
We compare our approach to several baselines with different relevancy criteria.
- Random: random selection
- BM25: computes lexical overlap as a relevancy score and selects the examples with the highest scores
- DSIR (Xie et al., 2023): weight candidate training data with n-gram features, and resample data based on the weights
- RDS: uses model’s hidden representations as features and selects the examples with the highest similarity scores
We surprisingly find that LESS is the only approach that consistently outperforms random selection. Other approaches, unfortunately, either provide minimal improvement over random selection (BM25), or underperform random selection. In the next section, we provide qualitative examples to have an in-depth understanding of why other approaches fail.
LESS selects examples with similar underlying task structures
We provide top selected examples by BM25, RDS and LESS for a TydiQA example. The TydiQA example presents a paragraph and a question in Bengali, and the goal is to locate an answer to the question within the given paragraph. BM25 and RDS select examples in Bengali, but these examples are related to a different task. In contrast, LESS selects a question-answering example written in English, which is more relevant to the target task.
This pattern holds true for the top examples selected for other questions. Upon further investigation, we discovered that the top examples selected by BM25 and RDS are predominantly in Bengali, whereas LESS consistently chooses examples in English that are specifically related to question answering. This observation suggests that LESS prioritizes examples that share a similar reasoning process, while the other approaches place too much emphasis on superficial cues such as language or topic, rather than the underlying task structure.

LESS circumvents surface-form cues to instead select examples with similar reasoning types as the validation data.
More computation on data selection enhances performance
Our ablations in the paper show that spending more computation in any of the steps of LESS can improve the performance of the method at the cost of additional runtime. For example, using a longer warmup phase in step 1, increasing the projected dimension in step 2, and aggregating the influence estimate over more model checkpoints can all improve performance at the cost of runtime and/or memory. We report results in a setting where the data selection cost is reasonable: selecting and training on the data requires less time than training on all available data. However, our results show that training on LESS data can even improve performance, so it may be worthwhile to invest more resources into the selection stage.
Past Works on Data Selection
In this section, we discuss many related works in-domain data selection and transfer data selection.4 Our goal is to briefly cover the many broad intuitions that can inform different data selection algorithms.
In-Domain Data Selection
As we mentioned before, the goal of data selection depends heavily on the setting. When ample labeled in-domain data is available (e.g., image classification in vision is an obvious case, pre-training data selection is also one), the goal is to identify the most representative subset of data, so much of the past work has sought to define the notion of “representative” datapoints. Sener & Severese 2018 explicitly defines this problem to be a core-set problem (Bachem et al., 2017, Tremblay et al., 2019), which aims to choose a set of datapoints such that each data point is close to at least one selected data point. Subsequent research has linked specific attributes of datapoints, such as being “easy to forget” (Toneva et al., 2019), exhibiting “large prediction error” (Paul et al., 2021), being “hard to memorize” (Feldman et al., 2020), being “redundant in clustering” (Birodkar et al., 2019) and having “uncertain predictions” (Chitta et al., 2019) with their representativeness and importance. Sorscher et al., 2022 consolidate these attributes under the category of hard examples, proposing that these instances are the most critical for effective training. One can also use gradient-based features (Mirzasoleiman et al., 2020, Wang et al., 2020, Killamsetty et al., 2021) for data selection. This naturally lends itself to a more general meta-learning formulation, which we discuss more below.
Pre-Training
In recent years, the pre-training and fine-tuning paradigm has proven to be an effective way to build large-scale foundation models. Unlike models trained with curated task-specific datasets like CIFAR or ImageNet, these models are trained with massive Internet-scraped data consisting of trillions of tokens or images. These two settings differ in two ways: (1) quality: web-scale datasets are generally heterogeneous in quality; and (2) scale: data selection has strong implications on efficiency in the foundational model era. We consider general pre-training data selection to be a form of in-domain data selection, as it aims to choose data that covers all potential use cases.
Algorithmic Filtering: Early in 2019, researchers have found that excluding high-perplexity examples from CommonCrawl could significantly boost training efficiency, since such examples are often nonsensical or of low quality (Wenzek et al., 2019, Marion et al., 2023). More sophisticated processing identified high-quality data by filtering domains and URLs, ensuring diversity, and removing redundancy (e.g., via MinHashLSH or semantic deduplication (Abbas et al., 2023)). Many popular datasets were constructed in this way, including C4 (Raffel et al., 2021), RefinedWeb (Penedo et al., 2023), SlimPajama (Shen et al., 2023), and more. Similar efforts have been explored for pre-training VIT models (Abbas et al., 2024).
LLM-Aided Filtering: An extreme form of algorithmic filtering is to explicitly prompt LLMs to generate data satisfying certain properties. The approach’s efficacy is clearest in the Phi-series models (Gunasekar et al., 2023, Javaheripi et al., 2024), which achieved strong performance on math and coding benchmarks with only 1.3B model parameters. While the Phi-series models focus on generating textbook-style data, other recent work has shown that rephrasing pre-training data to mimic the stylistic and informational density of Wikipedia articles markedly enhances the data’s cost-effectiveness (Maini et al., 2024). Aside from generating data, LLMs can also be used to judge the quality of data. Recent works such as QuRating (Wettig et al., 2024) and Ask-LLM (Sachdeva et al., 2024) aim to exploit capable language models to directly provide quality scores to data instances, offering a metric for evaluating their potential impact on model training.
Meta-Learning Formulation: Instead of relying on human notions of quality, one can also phrase in-domain and transfer data selection as meta-learning problems (Nguyen et al., 2020). The outer loop selects data for models in the inner loop to train on. Meta-learning approaches have traditionally been very computationally expensive. Recent work, dubbed datamodels (Ilyas et al., 2022), seeks to make this bi-level optimization problem more tractable by directly training a model to predict the test performance that would result from excluding or including a particular datapoint. Subsequent work (Park et al., 2023) made this approach computationally efficient, and recently, Engstrom et al., 2024 used this approach to score pre-training examples based on how they affect performance on a target set of examples. Our work, LESS, can be interpreted as one such meta-learning formulation for selecting data in the instruction tuning setting.
Instruction Tuning
Instruction tuning stands as a pivotal process in unlocking capabilities of pre-trained base models by further training the models to make them follow human instructions. Many works have assembled massive instruction tuning datasets. Some early datasets are human annotated (e.g., Open Assistant and Dolly), though recent trends mostly use completions from GPT models (e.g., Orca, ShardGPT, UltraChat etc.). The queries in these datasets cover a broad spectrum of topics, and could be as diverse as pre-training datasets. They are mostly used to build general-purpose chatbots.
Recently, a lot of works have shown that high-quality data is essential for instruction tuning. The pioneering work LIMA (Zhou et al., 2023) illustrates that a mere 1,000 meticulously selected high-quality human-curated examples could lead to marked performance improvements. Numerous studies have thus endeavored to automate the data selection pipeline, including strategies for choosing examples based on their naturalness (Cao et al., 2023), employing GPT-4 for quality scoring (Chen et al., 2023), enhancing data diversity (Bukharin et al., 2023, Liu et al., 2023), and ensuring broad coverage (Du et al., 2023). Additionally, some research has explored the benefits of prioritizing longer examples (Zhao et al., 2024), but it remains uncertain whether if this simply aligns on a surface level with the tendency of GPT to favor longer outputs (Wang et al., 2023).
Transfer Data Selection
Transfer data selection and in-domain data selection differ in purpose. While in-domain data selection aims to cover the properties of the entire dataset, transfer data selection focuses on enhancing the performance of a specific subdistribution of data. This shift in focus leads to a change in the selection criterion from representativeness to relevance.
In transfer data selection, the goal is to identify the most relevant data points from a large pool of available data. This approach is particularly useful for building domain-specific models or improving the performance of specific tasks or queries. To achieve this, a subset of target data is typically required to serve as an anchor for the data selection process. Previous works in this area include the study by Gururangan et al. (2020), which demonstrates the effectiveness of continued training on topic-specific pre-training data to improve performance on domain-specific downstream tasks. Another notable work is by Xie et al. (2023), which introduces a data reweighting approach based on the n-gram similarity between the source data and the target distribution. While these two works focus on aligning data with surface form cues (i.e., topic and ngram matching), LESS selects data that matches the underlying task or reasoning type.
Conclusion and Future Directions
Data plays a crucial role in determining the capabilities of trained deep models. In the in-domain setting, data selection aims to select a small yet representative dataset. Reducing the dataset size directly reduces the time required for training, which can be extremely useful when pre-training LLMs. On other hand, in the transfer setting, one seeks to solve tasks that do not have much data associated with them, and this requires filtering the dataset to identify a relevant subset to train on. Our method, LESS, selects data in the transfer setting to perform targeted instruction tuning, and it identifies the most relevant 5% of the dataset that can induce better performance than training on the full dataset. More broadly, we see data as being an important area of study for improving LLMs. Spending more compute on data selection (or, more broadly, data generation) in many different settings has proven to be very valuable, though one has to ensure that the cost of selection does not skyrocket. Data selection can also go beyond improving or preserving performance to attribute particular model behaviors to the training data. For example, a recent follow-up to LESS (He et al., 2024) identifies seemingly benign data that somehow breaks the safety of models during fine-tuning. We’re excited to see where data selection goes next!
Acknowledgements: LESS is co-authored with Suchin Gururangan, Sanjeev Arora, and Danqi Chen. We thank (in alphabetical order) Dan Friedman, Tianyu Gao, Lucy He, Austin Wang, Alex Wettig, and Howard Yen for their helpful feedback on this post!
Footnotes:
-
In some cases, the distribution of the training data may not match that of the evaluation data. However, the training data could still serve as a good approximation and correlates with the performance on the evaluation data. For instance, the pre-training loss measured on a held-out dataset, typically provides a reliable indication of the model’s performance on downstream tasks. Therefore, we still consider pre-training data selection as in-domain data selection. ↩
-
We use the efficient random projection implementation used in TRAK (Park et al., 2023). See their amazing codebase here! ↩
-
According to the derivation, the training gradients are normalized using the Adam update rule, and the validation gradients for the target instances are used as-is. Both are compressed via random projection. ↩
-
A recent survey paper provides a more comprehensive and formal treatment of data selection methods in the context of language models. ↩