Updated Fri Jan 19 08:46:47 EST 2024
Every aspect of this is representative of issues that you are likely to face in working with your own data. For instance, doing things manually instead of writing code is a tradeoff, based on imperfect information. So is deciding whether to learn a new tool to make experiments easier, or to write your own, or to just make do with ones you already know even though they aren't really right for the job.
Now discard everything but the plays. You could do this manually, or by finding where the irrelevant parts start and end and then writing a simple program to remove what you don't want. Use your favorite text editor to look at the file, and tools like grep to find things.
After you remove the poetry, how much is left, as a fraction of the original?
Do the following exercises using whatever combination of tools and techniques you like. As you go, make notes of things that worked well, that failed miserably, that were surprising, and so on. No need to submit anything, but be prepared to talk about it extemporaneously in class.
One early choice is whether to split the original file into separate files, one per play, with systematic names so you can use shell wildcards like *.txt to go through all the plays while still being able to easily see what applies to individual ones. I had originally thought that separate files would be better, but in the end just left things in one file; there was enough structure that I could separate the plays when necessary. Your mileage may vary.
What character set does this file use? This can matter, for example if your tools assume ASCII and the input is not.
Create a list of the unique characters in the input file
Summary statistics like raw counts of lines and words tell you something (like how much Shakespeare wrote):
Approximately how many lines, words and characters did Shakespeare write in all? How many of those are blank lines (or alternatively, how many are non-blank)?
How many plays did he write? You can count them by hand with the table of contents at the beginning of the original file, but do it with a program since you'll need one later on anyway. What text reliably marks the beginning of a play; alternatively, what text appears only once for each play? How can you use that to identify relevant parts of the text?
How many plays are there in this file? Print the titles
I did this with 4-6 lines of Awk; Python would be a few lines longer.
What's in each play? Write a program that, for each play, will count acts and scenes.
compute the number of acts compute the total number of scenes (ignore miscellany like prologs and epilogs)
It's marginally more work to compute scenes in each act, but a good exercise.
How many roles are there in each play?
compute the approximate number of dramatis personae in each play
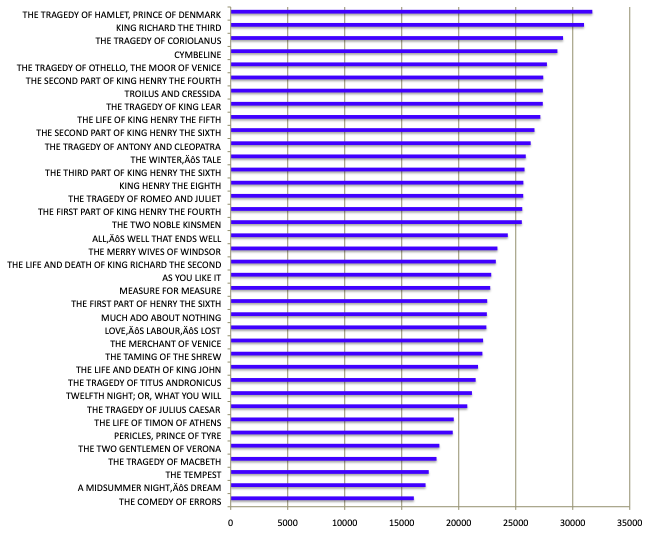
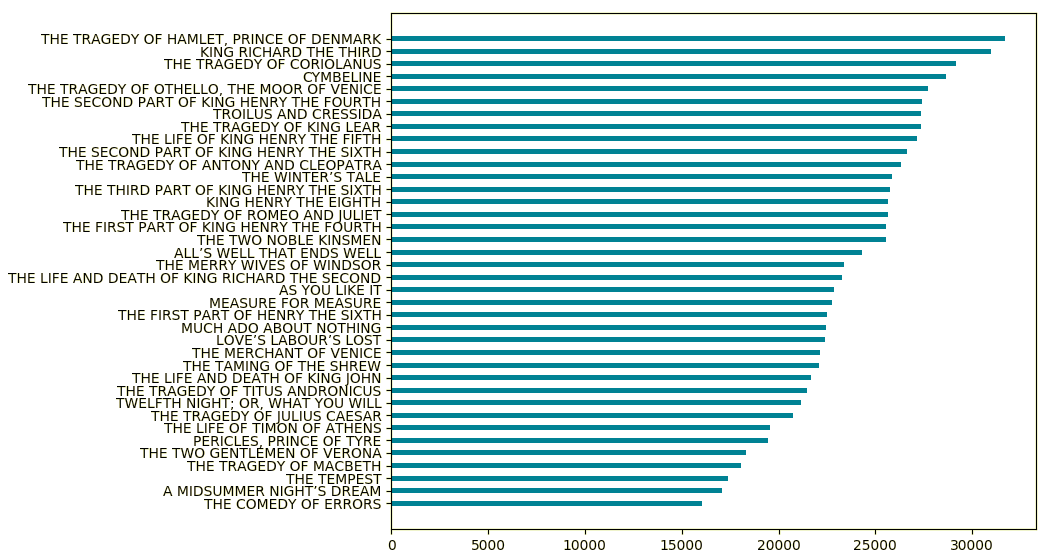
Count the words (very approximately is good enough) in each play.
Count the words
Who does the talking? What are the top ten most frequent speaker names?
compute the names of all speakers in all plays and how many times each name appearsHint: this is a one-liner if you know basic Unix tools!
Put your data into an Excel or Google spreadsheet. Your sheet should have four columns:
title number of acts number of scenes number of personae
Use CSV or TSV format for the columns, so it's easy to separate the titles from the counts.
My code for all of this (including titles) is one program with 20 lines of straightforward Awk. It's about 10-15 lines longer in Python since you have to write an input loop, and while loops are not as compact. The outputs are identical except for one word count.
Plot some simple graphs of your results. For example, here are the plays sorted in order of approximate word count with Excel:
and with matplotlib:
You might use a scatterplot to show the relationship between the number of lines and the number of characters (if there is one).
You might set up a Git repository for your work, as practice.