Now official
There should be no further changes except for clarifications and perhaps better explanations.
Due Thursday March 7 at 10:00 pm
Thu Feb 28 13:24:33 EST 2019
This assignment will walk you through some of the thinking, decision-making, and things that you need to deal with if you want to create a web or phone app. To summarize, there are myriad choices, lots of tradeoffs, and not many clearly "right" answers. That said, there are some common paths through the maze, or at least decisions that many people make in much the same way, sort of the path of least resistance. This assignment is meant to force you through at least one path from start to finish, so you at least understand what it's about even if you haven't tried many of the alternatives. For more background, W3Schools has a very helpful roadmap; check out the Github links on that page as well.
The whole picture is sometimes called the "full stack", in the sense that it encompasses all the technologies from user interface through server to database that one might use to make an app. By the end of this assignment, you could even claim that you have full-stack experience, though your veneer of knowledge would be exceedingly thin.
A bit of advice: hosting can be harder than you thought, so experiment early.
Providing better access to the Registrar's course data has been a perennial favorite in COS 333. In this assignment you will create a simple web service that displays the course number and title of the courses in a specific department or program. Queries include a department code like COS and optionally a course number like 126, and they return the course title. (This is a minimal version of an assignment in Spring 2018.)
The assignment has N parts, roughly corresponding to what you would do for a real project:
TASK: Things you should do will be marked like this paragraph. You do not have to do them in this order or even at all; we will only be evaluating the end product.
The information for one semester is on one Course Offerings page plus pages that it links to. You could retrieve the data by scraping the HTML and extracting the parts that you need, for example with a tool like Beautiful Soup. This approach works for many potential data sources but scraping is often hard -- formats are complex and change frequently, dynamic pages are hard to parse, and terms of service might impede. Scraping is usually a last resort.
Fortunately OIT provides a feed of the Course Offerings data in XML or JSON, which are well-structured tree-like representations of the information. JSON is simpler, more compact, and easy for humans to read, so we will use it here.
You can grab the whole semester with this curl command:
$ curl 'etcweb.princeton.edu/webfeeds/courseofferings/?fmt=json&term=current&subject=all'This returns about 2MB of text as a single long line. You can pretty-print it with a Python module called json.tool; a small sample can be found here.
$ python -m json.tool
Curl is great for experimenting and figuring out what information is coming back. You should learn its basics.
The solution is to use a package installer to keep software up to date, and a virtual environment to keep installed software for a project in one place on your computer so you can run all installed packages from this place. When you're done, removing a directory gets rid of everything.
There are multiple package managers for different languages and systems. For Python, pip is pretty much the standard, so if you are going to use Python for this assignment, you will have to install and use it. Once you've done that, it's easy to add further Python packages as necessary.
One of the first would be virtualenv. You don't actually need to use a virtual environment, but it's a good idea with little overhead, so think about it. To use virtualenv,
$ pip install virtualenv --user # once $ virtualenv venv # pick any name you like $ . venv/bin/activate ... [do all your work ... $ deactivate # this session
TASK: Install pip and virtualenv. It's recommended that you do your work on this assignment in a virtual environment.
A server is a program that listens for requests and sends back results. You can start with a server on your own computer, though you must eventually use a hosting service so your server is accessible to other people. Servers can be written in any programming language; the most common choice in 333 is Python.
Here's a basic server in Python2 that reads the OIT data into a data structure, then listens for requests and responds to them. You'll likely have to install the requests package first and some of its dependencies; use pip.
import SocketServer, SimpleHTTPServer, requests
class Reply(SimpleHTTPServer.SimpleHTTPRequestHandler):
def do_GET(self):
# The query arrives in self.path. The following line just echoes the query;
# replace it with code that generates the desired response.
self.wfile.write("query was %s\n" % self.path) # replace this line
all = []
def get_OIT(url):
r = requests.get(url)
if r.status_code != 200:
return ["bad json"]
return r.json()
def main():
global all
# Read OIT feed before starting the server.
oit = 'http://etcweb.princeton.edu/webfeeds/courseofferings/?fmt=json&term=current&subject=all'
all = get_OIT(oit)
print("server is listening on port 33333")
SocketServer.ForkingTCPServer(('', 33333), Reply).serve_forever()
main()
This starts a server listening on port 33333 and runs it forever. (Note that the call to SocketServer.ForkingTCPServer does not return, so it must be the last line of your main function.)
When the server receives a request, it is handled by the function do_GET in the Reply class. The version above just prints the value of the path instance variable, which is the query string. Your job is to replace that line with your code to return the search results.
TASK: Modify the server to read the JSON from the OIT feed (once) and respond to subsequent queries from users. Begin by upgrading the server above so it displays enough information that you know it's retrieving and parsing the JSON from OIT correctly.
The next job is to send queries to the server. We will use a convention called REST, in which a query is simply a string of characters, usually separated by slashes, that are appended to the URL used to access the server. Thus if your server is hosted at port 33333 at reg.example.com, it would be queried like this:
$ curl reg.example.com:33333/jrn $ curl reg.example.com:33333/cos/333
You can use your own computer to experiment; its name is localhost, and its IP address is 127.0.0.1. The port number is arbitrary; you can use anything from say 3000 to 633333.
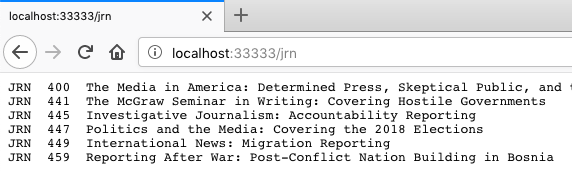
Queries like these can be sent by curl commands for experimenting, and from a browser interface using HTTP GET or POST requests, as you will do in the next section. In the interim, you can type queries into the address bar of a browser, like this:
The server receives a query from the client, parses it as necessary (for example, to separate "cos" from "333"), scans the OIT data, generates a response, and sends that back.
Empirically, this only works with Firefox at the moment; Chrome and Safari complain, though for different reasons.
Query matching:
TASK: Modify your server to respond to REST queries like the ones above by returning lines of text. If there are no matching courses or if the input is not valid (e.g., not 3 letters or not 3 digits after 3 letters), return a single blank line.
Suppose we want to count the number of times each department is mentioned in a query. That information has to be collected and stored by the server, and we want it to persist even if the server is stopped and then restarted later.
For something as simple as counts, we could just store the information in a file, but since using a database is a requirement for COS 333 projects, we're going to instead use a relational database in this assignment.
A relational database system holds its data in a set of one or more tables, each of which has a fixed number of attributes (columns) and a variable number of rows (the data items). For this assignment, we will use this simple table structure:
CREATE TABLE counts ( dept VARCHAR(10) PRIMARY KEY, counter INT );
Each query that mentions a 3-letter department code (whether valid or not) increments the count by one. After a sequence of queries, the database might contain something like this:
COS 10 REL 7 PHI 2 CLA 5 XYZ 1
The SQL language provides commands for creating a table originaly (as given above), querying the data, updating data values, and deleting it. SQL has a lot of features, but for this assignment you don't need much more than the following. SQL keywords are case-insensitive we've used upper case so you can see what they are.
SELECT * FROM counts;
SELECT * FROM counts WHERE dept = 'ele';
INSERT INTO counts VALUES('cos', 1);
UPDATE counts SET counter = 1 WHERE dept = 'vis';
DELETE FROM counts; -- careful! deletes everything
DELETE FROM counts WHERE dept = 'rel';
SQLite is a tiny ubiquitous SQL database system -- it's used in your phone, for example, and anywhere else where there is a need to manage structured data efficiently, reliably, and concurrently. The database itself is stored in a single file, though it has a lot of internal structure. MySQL, MariaDB (its open-source clone), and Postgres are more heavyweight SQL database systems that are better for larger-scale heavily-used systems. To get you started, you can download the file reg.db, which is an empty SQLite database. You can use this file with a standalone instance of the sqlite3 program, and from within Python by import sqlite.
In theory, all SQL database systems support the same query language, but provide their own metalanguage of control. It's usually not too hard to switch from one database system to another if required. Python has an SQLite module (import sqlite3) and you can use functions to execute SQL commands like those above. You can also run the sqlite3 command standalone to create the database originally and for experimenting.
Add two new REST endpoints, count and clear, to your server, with these semantics:
TASK: Use SQLite to create and maintain a database file reg.db with counts for each department as specified above. Each query for a 3-letter department code like rel, whether there is such a department or not, increments the count for that code, and each query like count or count/rel returns the value(s) even if they are zero.
In this part, you have to make a nicer web page, with a text entry box into which the user types the query, and a buttons for requesting the count and clearing the database. Pushing the submit button sends a request, and the response is displayed.

The count button itself returns all counts; if there is a 3-letter department code in the text box, it returns the count for that department. The clear button does the same but clears the corresponding department or all departments.
On the browser side, there's a wide range of options, from rolling your own with straight HTML and CSS to heavyweight tools that do a lot of the work for you, at the price of complexity and inflexibility.
The browser (client) side typically uses HTML and CSS for layout, and perhaps Javascript libraries for local computation and visual effects, and for communicating with a server. For HTML and CSS, the usual choices are Bootstrap and W3Schools W3.css. The latter is simpler and self-contained; Bootstrap seems to be getting more complicated over time. Most people will use one of these, since they both provide "responsive" features so your app will adapt gracefully to smaller screens like those on tablets and phones.
jQuery is one of the earliest Javascript libraries. It cleans up some ugly bits with a library of useful functions. Beyond that, you might use React (rather complicated) or Vue (similar but significantly simpler). Angular, another option, has a much steeper learning curve. These libraries tie the pieces of the browser interface together so that when something changes in one place, everything that depends on it automatically changes as well. This simplifies some kinds of code, at the price of having to learn a lot. None are needed for this assignment, though they might be good for a project.
TASK: use a responsive package like W3.css or Bootstrap so your page displays well on small screens like phones.
You have to have a server somewhere to respond to requests from other users. You can certainly use your own computer when you're getting started, but that doesn't work if you want anyone else to be able to use your system, or even if you want to use it yourself from other computers.
You could use some Princeton computer at CS or OIT, or OIT's myCpanel service. These are useful for experiments but they don't scale well, and myCpanel often has very dated software. They may also prohibit network access from off campus.
Most student projects are hosted on services like Heroku (easy, free for light loads), Amazon Web Services or Google Cloud Platform or Microsoft Azure (all more complicated, free to get started but only for a limited time), Digital Ocean (usually free with a coupon), and many others. There are also services for storing small amounts of data without processing, like Firebase or Github static pages. Each of these has its own good and bad points, including limitations on speed and storage and software, and potential costs in complexity and money.
There are an infinite number of tutorials on how to set up hosting; you are free to refer to as many as you like. I have yet to find one that is simultaneously simple, accurate, and up to date. Lance suggests this one.
Some hosting services will not preserve your database beyond some time period unless you explicitly use something big like Postgres. But SQLite seems to persist for a while on Heroku, and that's likely good enough for this assignment.
TASK: Put your server on a hosting service.
Server-side code often uses a framework, a library that takes care of a lot of the boilerplate needed to direct requests to the proper server functions, to generate formatted responses, and to communicate with a database system.
There are many frameworks. For Python, Flask is good for simple systems without a lot of complicated data or processing; it's a good back-end for phone-based apps. Bottle is a simpler analog of Flask that Professor Dondero uses when he teaches COS 333. Django is more heavyweight, appropriate when there are more complicated databases and client interactions. Many TigerApps have used Django, and it's widely used in The Real World.
If you want to pursue this option, use Flask or Bottle; Django is overkill. But this is only an assignment, not a project, so don't get too wrapped up in this aspect.
- XCode + Swift (or maybe Objective-C) for iPhones
- Android Developer Studio + Java for Android phones
- React Native + Javascript for both iOS and Android
If you want to take full advantage of everything that a phone provides, you need to write for the specific phone system: Swift for iOS for iPhones using XCode, or Java for Android phones using the Android Developer Studio. Both XCode and Android Developer Studio are heavyweight packages but they do a lot for you (especially XCode). But you are in effect creating the app for two utterly unrelated systems in two different languages, so it's like building two separate apps. Most student projects that take this path only have time for one kind of phone.
The alternative is to use a package like React Native, which lets you write your app in Javascript. That code is converted into either Java or Swift (or Objective-C?) that will run natively on the chosen phone. The positive is that you only have to write your code once and it works on both platforms. The downside is that you might not be able to get full access to everything that a specific kind of phone provides, and the user interface might not look as good as the native app or behave as well.
If you want to try one of these, React Native is likely to be easiest by quite a bit. As with the comments on frameworks above, don't get too wrapped up in this -- it's easy to blow more time than is necessary for the assignment.
We will test your program primarily by using curl with the URL of your hosted service, though we will also experiment with the browser interface to be sure it works and is responsive to different screen sizes. We may also test it locally if the hosted solution proves problematic (for you or for us).
Your REST interface should behave as shown earlier when a 3-letter department code and an optional 3-digit course number are provided. The special value count should return a list of department codes and counts, one per line; the special value clear should remove all codes and associated counts. Each of these may be followed by a slash and a 3-digit course number, in which case the request applies only to that course.
Submit the following files:
https://joe-college-a4.herokuapp.comWe will use this to access your implementation mechanically, so please be sure that it works if we just insert it verbatim into a curl command or paste it into a browser.
tar cf asgn4.tar ...list of all files and directories...We will use this to assess your server if for some reason there is a problem with your hosting. There will be a penalty if you don't get hosting to work, but we won't kill you.
Submit your files using the CS TigerFile system at http://tigerfile.cs.princeton.edu/COS333_S2019/asgn4.
Here are a couple of recent Hacker News discussions about how to approach similar projects.
https://news.ycombinator.com/item?id=18824993
https://news.ycombinator.com/item?id=18829557