Reinforcement learning
Bandit
Learner only observes the reward for the actual action taken, instead of the reward of all possible actions. The reward is often noisy since the learner interacts with an environment.
Example: advertisement placement. learner shows the user an advertisement, want the user to click on it and generate revenue
- missing rewards: learner does not get to see if the user would have clicked on other ads that are not shown
- noisy rewards: the user might click on a bad ad by accident, or not click on the good ones
Exploration exploitation trade-off. An agent can exploit by taking what seems to be the best action, or explore and gain more information on alternative actions. A particular simple form is the -greedy method, that always explore with probability .
One can reduce supervised learning to the contextual bandit setting by paying a factor of . Given dataset , we will withhold from the learner and instead only tell the learner if it predicted correctly.
- learner is given and makes a prediction .
- learner receives .
With agents that explore and learn under noisy and partial rewards, it is natural to consider agents that make a sequence of actions, and only receive a reward sometimes.
Markov decision process
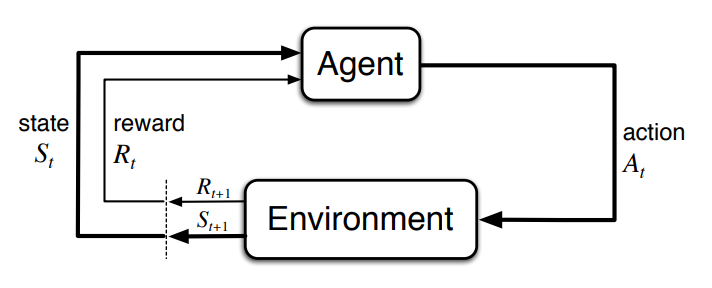
At step the environment is in state , agent takes actions in an environment and receive a reward based on the action. When this is rolled out in time steps,
When the environment is specified by the transition probability and the expected reward , the problem of computing what action to take in each state to maximize the total reward is called a Markov decision process (MDP). The solution is called a policy, which is a distribution of actions for each given state. When the policy is deterministic, it is just function from state to action .
Need for random policy. Suppose the states are arranged spatially as
left, next-to-mid, mid, next-to-mid, right, and the reward at mid is high.
Dice game. actions are quit and stay
quit: get reward 10, and endstay: get reward 4, and end if dice rolls 1 or 2 Should you always playstay?
Need for discounting. For example, we might want to maximize the lifetime earning of some ad placement method. The lifespan might be long, and in any event there is no natural ending. In this case, we are forced to consider the time value as well, and discount future rewards by a factor of .
Value of a policy
The value function of a policy is is the (expected) sum of all future reward starting with state and following policy . The value function and policy together satisfy the Bellman equation.
- This gives a set of linear equations, could just solve for
- alternatively, because the simple form, one can just do iterative updates until convergence
The complexity per round is .
Value iteration
The Bellman equation gives us the value function for a given policy. However, actually solving an MDP means we would like to compute the policy. We want
Instead, we can consider the value as a function of a particular action taken, and the Bellman equation for the optimal policy
As before, this can be computed iteratively, but the complexity per round is now a bit higher, at .
Exercise
- value of the dice game
- value of a grid game
Games. Reward (negative if the other player wins), only when the win condition is satisfied (3 in a row, column or diagonal).
In a symmetric game, an RL algorithm take both sides and play against itself with both sides learning. With a game that has clearly defined rules, RL is very attractive since infinite data is available.
- What are the states? is discounting necessary?
Limitations. Which problems are not captured by a MDP?
RL in NLP
Since RL is a very general framework, many NLP problems can be formulated in terms of RL. To better understand when we might need RL, it is worth considering why we did not need RL in many problems.
- language modeling
- pasing
Dialogue. Agent and customer take turns in a dialogue to solve a customer problem. Receive reward in the end based on if the problem was solved. Unfortunately, there is no good simulator for the customer since the only working NL processor is the human, and human in the loop means slow iterations and expensive data. Some important feedback is not easily converted to a reward e.g. “No, I meant …”, “Yes, please”.
TBC