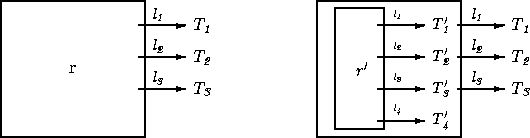Princeton University |
Computer Science 441 |
In Pascal get extreme position that procedures only take arrays w/exactly same dimensions as well as types.
Modula-2 starts opening up, by allowing different sizes of arrays as parameters, but still require same base type.
Restrictive since sort procedures will work with any ordered type.
Rather work with "polymorphic" functions and procedures.
Two main flavors of polymorphism: ad hoc and parametric (talk about subtype later).
Ad hoc also known as overloading. Done well it can make code easier to understand. E.g., "+" for real and integer addition.
Done poorly it can confuse and lead to errors, e.g. "+" for string concatenation.
Most languages provide some overloading (e.g., arith. operators, I/O), a few (e.g., Ada and C++) allow user to define overloaded operations (either infix or prefix).
E.g. in Ada, write
function "+"(m,n:Complex) return Complex is begin ... end;
Must provide a mechanism to support resolution of overloading - i.e. which actual operation does an instance refer to.
Two major ways of resolving:
Overloading is not essential and is easily abused. Useful when matches expectations from external notation. Confusing and unhelpful otherwise.
Parametric polymorphism usually considered a good thing.
These are almost always related to parameterized types.
E.g., sorting with array of T where T is ordered
Push, pop with stack of T.
Search of Binary search tree of T.
In ML, direct support for polymorphic functions on lists (parameterized).
Can define parameterized types through datatype definitions.
E.g.,
datatype 'a stack = Empty | Push of 'a * ('a stack)
Languages support two different forms of parametric polymorphism:
implicit
and explicit.
Differ on whether must supply type parameter.
Very clever type inference algorithm invented independently by Hindley and
Milner.
Collects all information about types of terms in expression
(assigning a variable if no info) and then tries to "unify" all information so
mutually consistent.
E.g.
fun map f nil = nil | map f (hd::tl) = (f hd):: (map f tl) map: 'a -> 'b -> 'c'b = 'd list (since second arg is "nil" or "hd::tl")
f: 'a = 'd -> 'e (since "f hd" is defined)
'c = 'e list (since result is a list, and, in 2nd clause, first element is "f hd")
Therefore, map: ('d -> 'e) -> ('d list) -> ('e list)
Overloading does not interact well with implicit polymorphism because often don't have type info necessary to disambiguate expressions.
Some ML designers (e.g., Harper) feel that it would have been better to omit overloading of built-in functions.
No type inference. If have polymorphic function, must explicitly pass type parameter.
E.g., fun map t u (f: t -> u) (l: t list): u list
Apply: map string int length ["a","help","Willy"] = [1,4,5]
Write type as
forall t. forall u. (t -> u) -> (t list) -> u list
Makes clear that t, u are type variables.
Can understand implicit polymorphic terms as abbreviations for explicit polymorphic terms. Compare with type of map in ML, above.
Explicit polymorphic terms more expressive!
Restrictions on polymorphism for ML.
Polymorphic functions can be defined at top-level or in let clauses, but polymorphic function expressions cannot be used as arguments of functions.
E.g.,
let fun id x = x in (id "ab", id 17) end;is fine, but can't write
let fun test g = (g [], g "ab") in test (fn x => x) end;In fact, can't even write:
fun test2 f = (f [], f 17);Gets confused since f is used with two different typings:
'a list -> 'b, int -> 'c and can't unify 'a list and int.
No problem writing this in explicit polymorphic language:
let fun test (g: forall t.t -> t): (int list, string) =
(g (int list) [], g string "ab")
in test (Fn t => fn (x:t) => x) end;
Write f: forall t. T, if f takes a type parameter U and
returns a value of type T[U/t].
Use Fn t => to
indicate parameter is a type.
Thus "id", defined by:
fun id t (x:t) = xhas type: forall t. t -> t.
A polymorphic function is one which takes a type parameter, which specializes it into a function of particular type. I.e., id T is function of type T -> T.
Think of "id" as representing a class of functions, each of which has uniform (parameterized) type.
While subtyping is usually associated with object-oriented languages, it also makes sense in more traditional functional or imperative languages. We will explore subtyping before beginning to examine object-oriented languages.
When can an element of one type be used in a context which expects another?
If an element of type T can be used whereever an element of type T' is expected then say T is a subtype of T' (write T <: T'). Another way of putting this is that any element of T can masquerade as an element of type T'.
Example: Integer <: Real, 1..10 <: Integer
Note this is only true of expressions, not variables!
Can understand definition of subtype as implying existence of a (well-behaved) implicit coercion from sub to supertype.
Well-behaved = homomorphism w.r.t. operators. I.e., ToReal: Integer -> Real
ToReal(2 + 3 * 4) = ToReal(2) + ToReal(3) * ToReal(4)Ada provides subranges of all primitive types (including reals): always inherit operations of base class.
Get subtypes of open array type by freezing bounds.
Get subtype of variant record by freezing variant.
Are there other reasonable subtypes?
Suppose have
type point = {x, y: real};
datatype colortype = Red | Blue | Yellow | Green;
type colorpoint = {x,y : real; color: colortype}
Is colorpoint <: point?
Suppose have
fun dist(p:point):real = sqrt(sqr(p.x) + sqr(p.y));Is there any reason this cannot be applied to cp:colorpoint?
The type of a record includes both the labels and types of each field. Thus a record with labels li of type Ti for 1 <= i <= n has a type which can be written in the form {li:Ti}1 <= i <= n. For example, the record {name = ``jane'',age = 12} has type {name: String; age: Integer}.
Suppose we have two immutable (i.e., fields can't be updated) record types, R' and R, with R' <: R. In order for elements of R' to masquerade as elements of R, expressions of type R' need to support all of the operations applicable to expressions of type R.
The only operation available on a record is to extract a labeled field.
For ![]() to masquerade as
to masquerade as ![]() ,then, for each field
,then, for each field ![]() of
of ![]() ,
, ![]() must also contain a field
must also contain a field
![]() . Moreover the type of that field must be a subtype of the
corresponding field in
. Moreover the type of that field must be a subtype of the
corresponding field in ![]() , since if
, since if ![]() then
then ![]() must be usable in any context in which the same field selection of an
element of type
must be usable in any context in which the same field selection of an
element of type ![]() makes sense.
In Figure 1 we show a record
makes sense.
In Figure 1 we show a record
![]() masquerading as
a record of type
masquerading as
a record of type ![]() .
Notice that the result of extracting the
.
Notice that the result of extracting the ![]() field of
field of ![]() must be
able to be treated as being of type
must be
able to be treated as being of type ![]() .Notice also that type
.Notice also that type ![]() may have more
labeled fields than
may have more
labeled fields than ![]() (since the extra fields don't get in the way of
any of the operations applicable to
(since the extra fields don't get in the way of
any of the operations applicable to ![]() ).
).
Thus a subtype of a record may have labeled fields whose types are a subtype of the original, and may also have more fields than the original record type. We write this formally as follows:
![]()
For example, if ![]() , then
, then
![]()
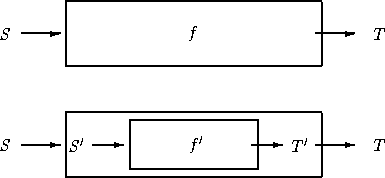
Suppose we have a function ![]() with type Func(S): T. In order
to use an element,
with type Func(S): T. In order
to use an element, ![]() , of type
, of type
![]() in place of
in place of ![]() , the function
, the function ![]() must be able to accept an
argument of type
must be able to accept an
argument of type ![]() and return a value of type
and return a value of type ![]() . See Figure
2. But
. See Figure
2. But ![]() is defined to
accept arguments of type
is defined to
accept arguments of type ![]() . Now
. Now ![]() can be applied to
an argument,
can be applied to
an argument, ![]() , of type
, of type ![]() if
if ![]() .
In that case, using subsumption,
.
In that case, using subsumption, ![]() can be treated as an element of
type
can be treated as an element of
type ![]() , making
, making ![]() typable. Similarly, if the output of
typable. Similarly, if the output of
![]() has type
has type ![]() then
then ![]() will guarantee that
the output can be treated as an element of type
will guarantee that
the output can be treated as an element of type ![]() . Summarizing,
. Summarizing,
![]()
Again assuming that ![]() , we get that
, we get that
![]()
![]()
Procedure types, written ![]() , may be subtyped as though they
were degenerate function types that always return a default type
, may be subtyped as though they
were degenerate function types that always return a default type ![]() , which has only a single value. Thus
, which has only a single value. Thus
![]()
Notice that the ordering of parameter types in function and procedure subtyping is the reverse of what might initially have been expected, while the output types of functions are ordered in the expected way. We say that subtyping for parameter types is contravariant (i.e., goes the opposite direction of the relation being proved) while the subtyping for result types of functions is covariant (i.e., goes in the same direction). The contravariance for parameter types can be initially confusing, because it is permissible to replace an actual parameter by another whose type is a subtype of the original. However the key is that in the subtyping rule for function types it is the function, not the actual parameter, which is being replaced.
Suppose we have a variable ![]() of type
of type ![]() (i.e., an expression of
type
(i.e., an expression of
type ![]() ) that we wish to have masquerade as a variable of
type
) that we wish to have masquerade as a variable of
type ![]() . See Figure 3. It is common to think of a
variable of type
. See Figure 3. It is common to think of a
variable of type ![]() as having two values: an L-value and an
R-value. The L-value is the location corresponding to the variable, while
the R-value is the value of type
as having two values: an L-value and an
R-value. The L-value is the location corresponding to the variable, while
the R-value is the value of type ![]() actually stored there.
actually stored there.
Variables can be used in both value-supplying and value-receiving contexts.
A value-supplying context is one that requires a value of type ![]() (i.e., the R-value of the variable).
This is illustrated in the figure by the operation (arrow) labeled
``val'' coming out
of the variable (representing the R-value of the variable).
By the definition of subtype, in order for a variable
(i.e., the R-value of the variable).
This is illustrated in the figure by the operation (arrow) labeled
``val'' coming out
of the variable (representing the R-value of the variable).
By the definition of subtype, in order for a variable ![]() of type
of type
![]() to be able to
masquerade as a value of type
to be able to
masquerade as a value of type ![]() in all contexts of this kind, we
need
in all contexts of this kind, we
need ![]() . This should be clear from the right-hand
diagram in the figure, where in order for
. This should be clear from the right-hand
diagram in the figure, where in order for ![]() to provide a compatible value
using the
to provide a compatible value
using the ![]() operator,
operator, ![]() .
.
A value-receiving context is one in which a variable of
type ![]() is assigned to, e.g., a
statement of the form
is assigned to, e.g., a
statement of the form ![]() , for
, for ![]() an expression of
type
an expression of
type ![]() . This is illustrated in the figure by an arrow labeled
``:='' going into the variable.
In this context we will be interpreting the variable as a
reference or location (i.e., the L-value) in which to store a value.
We have already seen above
that an assignment like this is type safe if
. This is illustrated in the figure by an arrow labeled
``:='' going into the variable.
In this context we will be interpreting the variable as a
reference or location (i.e., the L-value) in which to store a value.
We have already seen above
that an assignment like this is type safe if ![]() has a type that
is a subtype of the type of the variable
has a type that
is a subtype of the type of the variable ![]() .
Thus if we wish to use a variable of type
.
Thus if we wish to use a variable of type ![]() in all contexts of this
form, we must ensure that
in all contexts of this
form, we must ensure that ![]() . Again this should be
clear from the right-hand diagram in the figure.
. Again this should be
clear from the right-hand diagram in the figure.
Thus for a variable of type ![]() to masquerade as a variable of
type
to masquerade as a variable of
type ![]() in value-supplying contexts we must have
in value-supplying contexts we must have ![]() , while its use in value-receiving contexts require
, while its use in value-receiving contexts require ![]() . It follows that there are no non-trivial subtypes of variable
(reference) types. Thus,
. It follows that there are no non-trivial subtypes of variable
(reference) types. Thus,
![]()
Another way of understanding the behavior of reference and function types under subtyping is to consider the different roles played by suppliers and receivers of values. Any slot in a type expression that corresponds to a supplier of values must have subtyping behave covariantly (the same direction as the full type expression), while any slot corresponding to a receiver of values must behave contravariantly (the opposite direction). Thus L-values of variables and parameters of functions, both of which are receivers of argument values, behave contravariantly with respect to subtyping. On the other hand, the R-values of variables and the results of functions, both of which are suppliers of values, behave covariantly. Because variables have both behaviors, any changes in type must be simultaneously contravariant and covariant. Hence subtypes of reference types must actually be equivalent.
The subtyping relation among object types can be rather subtle. In simple type systems like those used in Java and C++, object types are considered subtypes when the record of method types of the subtype extends that of the supertype. That is, a subtype may contain more methods than the supertype, but the corresponding methods must have the same types. This is more restrictive than the definition of subtype for record types given above. We will see later that there is no need for such a restrictive notion of subtyping.