
Lab 6: Artificial Intelligence and Machine Learning
Sat Oct 24 11:17:24 EDT 2020© xkcd.com
The combination of steadily increasing computing power and memory with a huge amount of data has made it possible to attack many long-standing problems of getting computers to do tasks that normally would require a human. Artificial intelligence, machine learning, and natural language processing (AI, ML, NLP) have been very successful for games (computer chess and Go programs are better than the best humans), speech recognition (think Alexa and Siri), machine translation, and self-driving cars.
There are zillions of books, articles, blogs and tutorials on machine learning, and it's hard to keep up. This overview, Machine Learning for Everyone, is an easy informal introduction with no mathematics, just good illustrations. YMMV, of course, but take a look.
This lab is an open-ended exploration of a few basic topics in NLP with a taste of ML. The hope is to give you at least some superficial experience, and as you experiment, you should also start to see how well these systems work, or don't. Your job along the way is to answer the questions that we pose, based on your experiments. Include images that you have captured from your screen as appropriate. Submit the result as a web page, using the mechanisms that you learned in the first two labs. No need for fancy displays or esthetics; just include text and images, suitably labeled. Use the template in the next section so we can easily see what you've done.
This is a newish lab, so it still has rough edges. Don't worry about details too much, but if you encounter something that seems seriously wrong, please let us know. Otherwise, have fun and see what you learn.
HTML template for your submission
Part 1: Word Trends and N-grams
Part 2: Language Tools
Part 3: Sentiment Analysis
Part 4: Text Generation
Part 5: Machine Translation
Part 6: Machine Learning
Submitting your work
| In this lab, we will highlight instructions for what you have to submit in a yellow box like this one. |
For grading, we need some uniformity among submissions, so you must use
this template
to collect your results as you work through the lab:
The Google Books project has scanned millions of books from
libraries all over the world. As the books were scanned, Google used
optical character recognition on the scanned material to convert it into
plain text that can be readily searched and used for language studies.
Google itself provides a web-based tool, the
Google Books Ngram Viewer,
that shows how often words and phrases have been used in a variety
of corpora. (An n-gram is just a phrase of n words that occur in
sequence.)
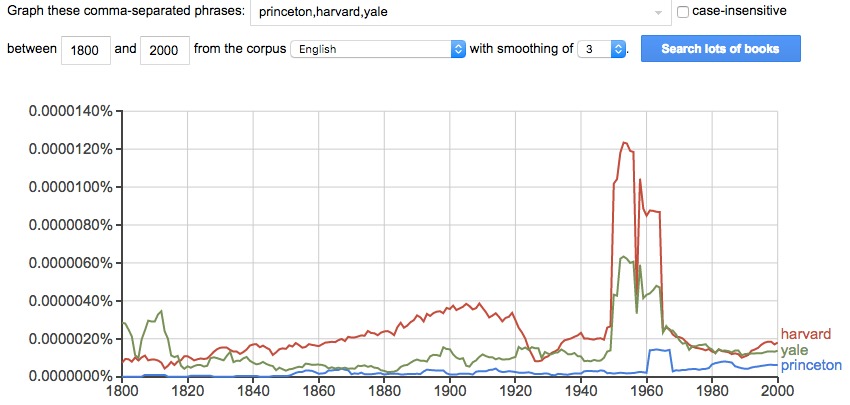
Word usage over time is often revealing and interesting. For
example, the graph of "harvard, princeton, yale" shows that "Harvard"
occurred much more often than "Yale", which in turn was much more
frequent than "Princeton" in the overall corpus. (Sorry, Princeton
students, but that's the way it is.) One also wonders why the peak
of interest in Harvard and Yale in 1945 to the early 1960s.
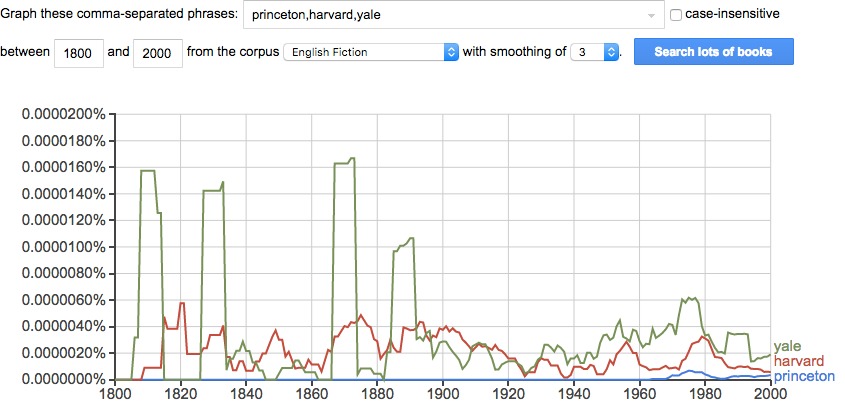
But the same search over "English Fiction" shows quite
a different story:
What's with Yale??? Those four big peaks in the 1800s are
the kind of unexpected result that might
raise questions and lead to further exploration.
In this section of the lab, your task is to play with the n-gram
viewer and provide a handful of results that you found interesting or
worth further exploration. What you look at is up to you, though
general areas might include names of places or people, major events,
language evolution, correlation of words and phrases with major world
events or social trends. You must provide at least two graphs that use some
of the advanced features described on the
how it works page.
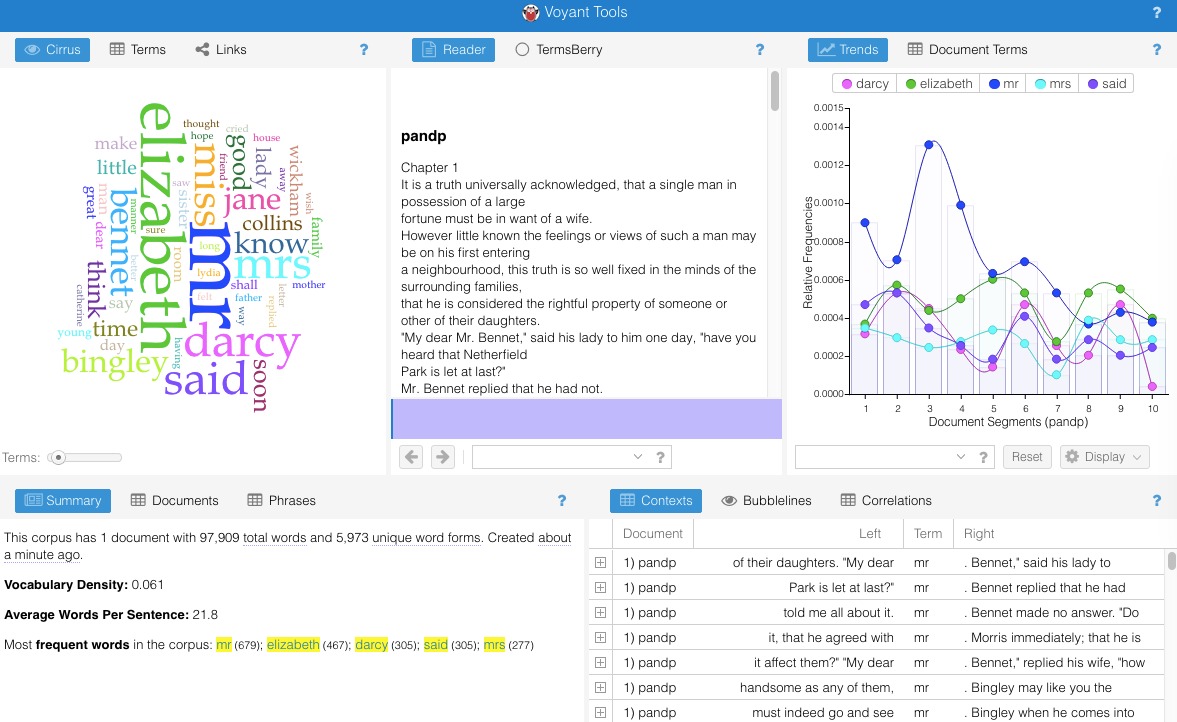
The Voyant system is widely
used in digital humanities. It provides tools for counting things in
documents and visualizing trends and associations among the words in one
or more documents.
Start it up, examine either the Jane Austen or Shakespeare corpora
that are already present (or both if you find it fun). Who used a
bigger vocabulary? Who wrote longer sentences?
Now upload a text that you are interested in, for example a single
novel or historical document. It should be of reasonable size, at least
10,000 words.
(Pride and Prejudice
is about 120,000 words,
Jane Eyre is 185,000,
Moby Dick is 210,000.)
You can use these if you have no specific literary interest,
but it might be more fun to grab something that appeals to you from a site like
Project Gutenberg.
(It's ok to use whatever text you used in the previous lab.)
Capture a word cloud ("Cirrus") that you like and include it in
your ongoing report.
Pick two of the many tools that Voyant provides,
and use them to produce some images and perhaps insights that you
found interesting, illustrative, appealing, or whatever.
(Voyant handles other languages besides English, if you'd like
to explore that aspect.)
The tools are available from the tiny icon that looks like
a perspective view of 4 panes; it comes and goes at the top
right of various windows.
"Sentiment analysis" refers to the process of trying to determine
whether a piece of text is fundamentally positive or negative;
this has many applications in trying to understand customer feedback
and reviews, survey responses, news stories, and the like.
Sentimood
is a simple-minded sentiment analyzer that basically just counts
words with generally positive or negative connotations and computes
some averages. You can see the list of words and their sentiment value
by "View Source" or clicking the sentimood.js file in your browser.
Paste some text into the window and it will give you a score that
indicates whether the text is positive or negative in tone, along with
the words that led it to its conclusion. There's no limit to how much
text you can give it, but a few hundred words is plenty.
One problem with Sentimood is that it doesn't understand English at
all; it's just counting words. Could we do better by parsing sentences,
perhaps to detect things like negation ("He is not an idiot") or
qualification by a clause ("A bit slow but certainly not an idiot") or
irony ("My, that is a baby, isn't it?").
More sophisticated sentiment analyzers sometime do a better job of parsing English, and thus
are
better at assessing sentiment, though they are easily fooled.
For example,
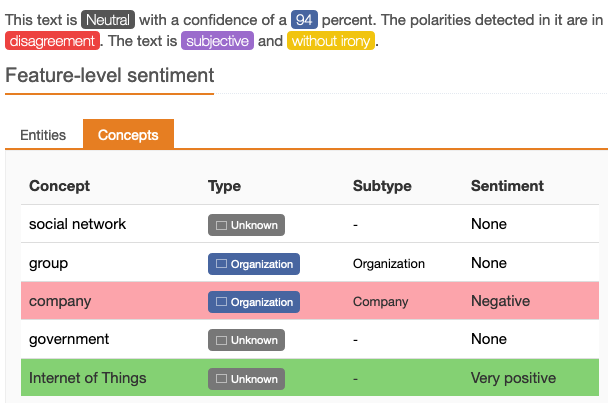
this demo
of a commercial service might best be described as "mixed." The input
Find two or three words in Sentimood's list that could be either positive
or negative, depending on context and interpretation.
Find two or three words where you think the weighting is seriously
wrong?
Try some sentences from literature, your own writing, tweets, or
whatever, with both Sentimood and the commercial analyzer.
Give two examples of sentences where they agree and both appear to be correct.
(If you wish, try to find another sentiment analyzer and use it instead.)
Give two examples where they differ markedly in their assessment.
Give two examples where they agree and both appear to be clearly wrong.
One aspect of such a test would be whether the program
can produce text that appears to have been generated by a
human. Two interesting sites provide glimpses of what might
be possible.
The first is TalkToTransformer,
which generates plausible continuations from a prompt text, using a
model of language that comes from a machine-learning algorithm
trained on a very large corpus of real text.
Try TalkToTransformer with some prompts, and see if you can
get it to produce something both interesting and believable.
A second area where the Turing Test seems especially apposite
is in the generation of modern poetry, that is, poetry that is
free of traditional constraints like meter, rhythm, and rhyme.
The site Botpoet.com is a
Turing Test of sorts: it presents random poems that were written
either by a human or a program, and asks you to decide which;
after each guess, it tells you what others thought. (Warning: it's
a fun site and you can waste a lot of time on it.)
Run botpoet.com 10 times, and
for each run, make your guess,
record how well you did and how well others did,
and screenshot the result (so you can remember what happened).
Give your best example of input to TalkToTransformer and the
output it produced.
Give a summary of your experiments with Botpoet. What was the
best imitation you saw? Explain why you
enjoyed it, were fooled, or whatever else you found interesting or
surprising.
The classic challenge is translating the English expression "the
spirit is willing but the flesh is weak" into Russian, then back to
English. At least in legend, this came out as "the vodka is strong but
the meat is rotten." Today, the Russian is "дух желает, но плоть слаба",
and the English is the same as the original.
(This result was different a year ago, and may well be different
by the time you try it.)
In this section, you have to experiment with
Google Translate
to get a sense of what works well today and what is not quite
ready to replace people.
Try 3 or 4 inputs from different sources, like the first lines of
novels, or papers you've written, or news stories, or tweets. Using Google
Translate, run them through another language that you know and then back to
English. Include at least two examples that work well and two that are
spectacularly wrong.
How well does Google do on your chosen language? Would it be useful
in practice? How about some other language that you know something
about?
Repeat the exercise with a sequence of two other languages, so that
for example you go from English to Twi to Urdu to English.
After training, the algorithm classifies new items, or predicts
their values, based on what it learned from the training set.
There is an enormous range of algorithms, and much research in
continuing to improve them. There are also many ways in which machine
learning algorithms can fail -- for example, "over-fitting", in which
the algorithm does very well on its training data but much less well on
new data -- or producing results that confirm biases in the training
data; this is an especially sensitive issue in applications like
sentencing or predicting recidivism in the criminal justice system.
One particularly effective kind of ML is called "deep learning"
because its implementation loosely matches the kind of processing
that the human brain appears to do. A set of neurons observe low-level features;
their outputs are combined into another set of neurons that observe
higher-level features based on the lower level, and so on.
Deep learning has been very effective in image recognition, and
that's the basis of this part of the lab.
Google provides
Teachable Machine,
an interface that uses the camera on a computer to train a neural
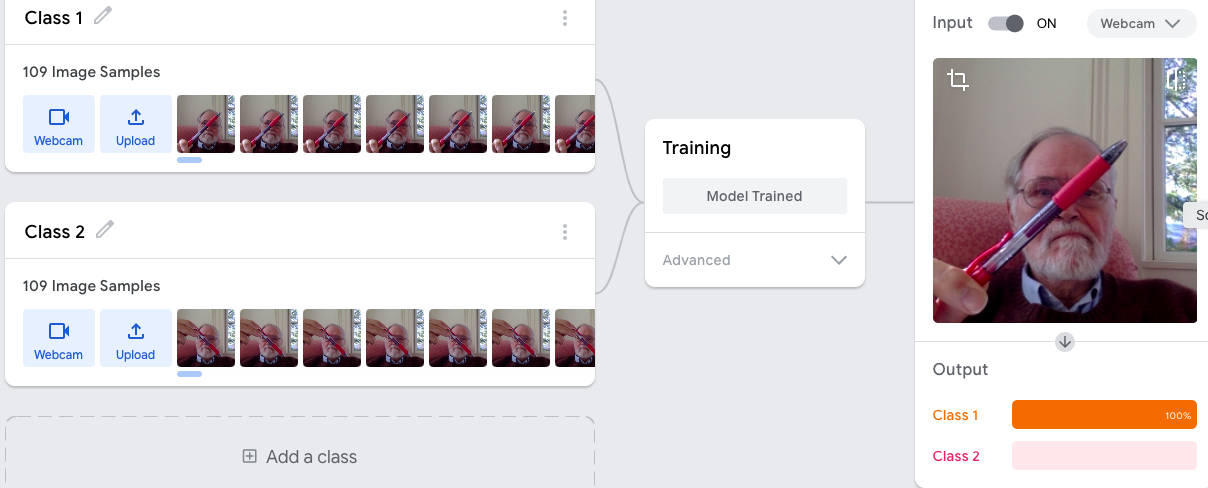
network on multiple visual or auditory inputs; the interface looks like this:
I trained the network on two images, holding a pen in one
of two orientations. It's an easy case, and the recognizer is quite good at
distinguishing them.
For each experiment, describe what you tried, why you chose it, and
how well it worked. How many training examples were necessary? How did
it improve, if at all, with more training?
Include a screenshot like the one above.
Make sure your lab6.html, including all images, is accessible at
https://your_netid.mycpanel.princeton.edu/lab6.html.
Ask a friend to view your page and check all the links from his or her
computer.
When you are sure that your page is displaying correctly, upload
your lab6.html and other files to
https://tigerfile.cs.princeton.edu/COS109_F2020/Lab6.
HTML template for your submission
<html>
<title> Your netid, your name </title>
<body>
<h3> Your netid, your name </h3>
Any comments that you would like to make about the lab,
including troubles you had, things that were interesting,
and ways we could make it better.
<h3>Part 1</h3>
<h3>Part 2</h3>
<h3>Part 3</h3>
<h3>Part 4</h3>
<h3>Part 5</h3>
<h3>Part 6</h3>
</body>
</html>
Put a copy of this in a file called lab6.html and as you work
through the lab, fill in each part with what we ask for, using HTML tags
like the ones that you learned in the first few labs.
Part 1: Word Trends and N-grams
Include at least two graphs that use some advanced feature of the Ngram
viewer, with a paragraph or two that explains what you did, what
advanced feature was used, and what your graphs show.
Part 2: Language Tools
Submit some combination of a couple of paragraphs of text and
at least two images, including
The book(s) you picked
A word cloud
The tools that you found most useful or insightful
The displays that you particularly liked
The course will have fundamentally the same structure as in previous
years, but lectures, case studies and examples change every year
according to what's happening. Stunning amounts of our private lives
are observed and recorded by social networks, businesses and
governments, mostly without our knowledge, let alone consent. Major
companies like Amazon, Apple, Facebook, Google and Microsoft are duking
it out with each other on technical and legal fronts, and with a variety
of governments. Shadowy groups and acronymic agencies routinely attack
us and each other; their potential effect on things like the upcoming US
elections is way beyond worrying. The Internet of Things promises
greater convenience at the price of much greater cyber perils. The
careless, the clueless, the courts, the congress, the crackpots, and the
criminal (not disjoint groups, in case you hadn't noticed) continue to
do bad things with technology. What could possibly go wrong? Come and
find out.
is characterized this way:
Part 4. Text Generation
We've talked about the Turing Test, which is based on the idea
that if a program behaves in such a way that an observer can't
tell whether it's a human, then it's behaving intelligently.
Part 5: Machine Translation
Computer translation of one human language into another is a very
old problem. Back in the 1950s, people confidently predicted that
it would be a solved problem in the 1960s. Sadly, we're not there
yet, though the situation is enormously better than it was,
thanks to lots of computing power and very large collections of
text that can be used to train machine-learning algorithms.
Part 6: Machine Learning
"Machine learning algorithms can figure out how to perform important
tasks by generalizing from examples."
Most machine-learning algorithms have a similar structure. They "learn"
by processing a large number of examples that are labeled with the
correct answer, for example, whether some text is spam or not, or which
digit a hand-written sample is, or what kind of animal is found in a
picture, or what the price of a house is. The algorithm figures out
parameter values that enable it to make the best classifications or
predictions based on this training set.
Using the deep learning link above, do two distinctly different
projects using the camera and/or microphone in your computer. This might be
images of yourself in various attire, or of you and friends, or
singing, or lots of other things -- be imaginative!
Submitting Your Work