WordNet is a semantic lexicon for the English language that is used extensively by computational linguists and cognitive scientists; for example, it was a key component in IBM's Watson. WordNet groups words into sets of synonyms called synsets and describes semantic relationships between them. One such relationship is the is-a relationship, which connects a hyponym (more specific synset) to a hypernym (more general synset). For example, a plant organ is a hypernym of carrot and plant organ is a hypernym of plant root.
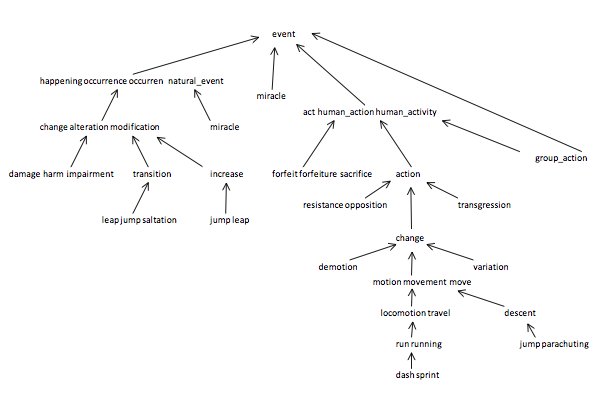
The WordNet DAG. Your first task is to build the wordnet digraph: each vertex v is an integer that represents a synset, and each directed edge v→w represents that w is a hypernym of v. The graph is directed and acyclic (a DAG), though not necessarily a tree since a synset can have several hypernyms. A small subgraph of the wordnet digraph is illustrated below.
We now describe the two data files that you will use to create the wordnet digraph. The files are in CSV format: each line contains a sequence of fields, separated by commas.
means that the synset { AND_circuit, AND_gate } has an id number of 45 and it's gloss is a circuit in a computer that fires only when all of its inputs fire. The individual nouns that comprise a synset are separated by spaces (and a synset element is not permitted to contain a space).45,AND_circuit AND_gate,a circuit in a computer that fires only when all of its inputs fire
171,22798,57458
means that the the synset 171 ("Actifed") has two hypernyms: 22798 ("antihistamine") and 57458 ("nasal_decongestant"), representing that Actifed is both an antihistamine and a nasal decongestant. The synsets are obtained from the corresponding lines in the file synsets.txt.
171,Actifed,trade name for a drug containing an antihistamine and a decongestant... 22798,antihistamine,a medicine used to treat allergies... 57458,nasal_decongestant,a decongestant that provides temporary relief of nasal...
Implement an immutable data type WordNet with the following API:
Your data type should use space linear in the input size (size of synsets and hypernyms files). The method isNoun() should run in time logarithmic (or better) in the number of nouns. The method glosses() should run in time logarithmic (or better) in the number of synsets, per gloss returned. The methods distance() and sap() should run in time linear in the size of the wordnet digraph.// constructor takes the name of the two input files public WordNet(String synsets, String hypernyms) // an iterable containing all of the glosses associated with the noun's synsets public Iterable<String> glosses(String noun) // is the word a WordNet noun? public boolean isNoun(String word) // distance between nounA and nounB (defined below); -1 if infinite public int distance(String nounA, String nounB) // a synset (second field of synsets.txt) that is the common ancestor of nounA and nounB // in a shortest ancestral path (defined below); null if no such path public String sap(String nounA, String nounB)
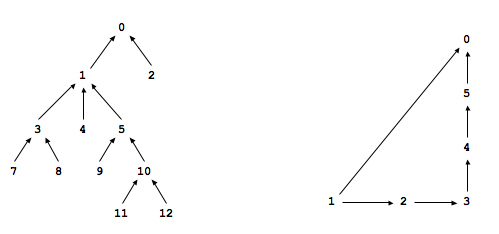
Shortest ancestral path. An ancestral path between two vertices v and w in a digraph is a directed path from v to a common ancestor x, together with a directed path from w to the same ancestor x. A shortest ancestral path is an ancestral path of minimum total length. For example, in the digraph at left, the shortest ancestral path between 3 and 11 has length 4 (with common ancestor 1). In the digraph at right, one ancestral path between 1 and 5 has length 4 (with common ancestor 5), but the shortest ancestral path has length 2 (with common ancestor 0).
Implement an immutable data type SAP with the following API:
You data type should use space proportional to E + V. All methods (and the constructor) should take time proportional to E + V in the worst case, where E and V are the number of edges and vertices in the digraph, respectively.// constructor takes a digraph (not necessarily a DAG) public SAP(Digraph G) // length of shortest ancestral path between v and w; -1 if no such path public int length(int v, int w) // a common ancestor of v and w that participates in a shortest ancestral path; -1 if no such path public int ancestor(int v, int w) // length of shortest ancestral path between any vertex in v and any vertex in w; -1 if no such path public int length(Iterable<Integer> v, Iterable<Integer> w) // a common ancestor that participates in shortest ancestral path; -1 if no such path public int ancestor(Iterable<Integer> v, Iterable<Integer> w)
Test client. The following test client takes the name of a digraph input file as as a command-line argument, constructs the digraph, reads in vertex pairs from standard input, and prints out the length of the shortest ancestral path between the two vertices and a common ancestor that participates in that path:
public static void main(String[] args) {
In in = new In(args[0]);
Digraph G = new Digraph(in);
SAP sap = new SAP(G);
while (!StdIn.isEmpty()) {
int v = StdIn.readInt();
int w = StdIn.readInt();
int length = sap.length(v, w);
int ancestor = sap.ancestor(v, w);
StdOut.printf("length = %d, ancestor = %d\n", length, ancestor);
}
}