Homework #5
|
Fall 2004
|
Special late policy: In counting late days, we will skip Thanksgiving day and the Friday after Thanksgiving. In other words, homeworks turned in by 11:59pm on Wednesday, November 24 will count as one day late (as usual), but homeworks turned in by 11:59pm on Saturday, November 27 will count as only two days late. As usual, no homeworks will be accepted more than five "days" late, which means they will not be accepted after Tuesday, November 30.
For this homework only, if you are out of the Princeton area over break, you may mail or email the written part of the assignment to Zafer. If mailed, your homework is considered submitted on the post mark date, and should be sent to this address: Zafer Barutcuoglu, Princeton University, Department of Computer Science, 35 Olden Street, Princeton, NJ 08544. (It would be wise to send him email at the same time you mail your assignment so that he can look out for it; also, save a photocopy of your work.)
See instructions on the assignments page (as well as the special instructions above) on how and when to turn these in. Approximate point values are given in parentheses. Be sure to show your work and justify all of your answers.
1. (15) Consider a two-bit register. The register has four possible states: 00, 01, 10 and 11. Initially, at time 0, the contents of the register is chosen at random to be one of these four states, each with equal probability. At each time step, beginning at time 1, the register is randomly manipulated as follows: with probability 1/2, the register is left unchanged; with probability 1/4, the two bits of the register are exchanged (e.g., 01 becomes 10); and with probability 1/4, the right bit is flipped (e.g., 01 becomes 00). After the register has been manipulated in this fashion, the left bit is observed. Suppose that on the first three time steps, we observe 0, 0, 1.
2. (10) Exercise 15.1 in R&N.
3. (15) Exercise 15.3 in R&N. However, you can skip the last question in part d.
4. (10) Exercise 15.4 in R&N.
5. (10) (This is a variation on R&N Exercise 16.3.) Bernoulli explained the St. Petersburg paradox by suggesting that the utility of money is on a logarithmic scale, i.e., that the utility of having $n is a lg n + b.
This assignment is about hidden Markov models (HMMs) and their many potential applications. The main components of the assignment are the following:
There is also an optional part to this assignment involving second-order Markov models, as described below.
The first part of the assignment is to build an HMM from data. Recall that an HMM involves hidden state that changes over time, as well as observable evidence, henceforth called the output of the HMM. An HMM is defined by three sets of probabilities:
Regarding item 3, in this assignment, we will assume that there is a single dummy start state, distinct from all other states, and to which the HMM can never return. Even so, you will need to estimate the probability of making a transition from this dummy start state to each of the other states (this is implicit in part 2, but may need to be done explicitly by your program).
For items 1 and 2, your job will be to compute estimates of these probabilities from data. We are providing you with training data consisting of one or more sequences of state-output pairs, i.e., sequences of the form x[1], e[1], x[2], e[2], ..., x[n], e[n]. During this training phase, we assume that the state variables are visible. Given these sequences, you need to estimate the probabilities that define the HMM. For instance, to estimate the probability of output o being observed in state s, you might simply count up the number of times that output o appears with state s in the given data, and divide by a normalization constant (so that the probabilities of all outputs from that state add up to one). In this case, that normalization constant would simply be the number of times that state s appears at all in the data.
Although this approach corresponds to the meaning of a conditional probability, when making estimates of this sort, it is often preferable to smooth the estimates. To see what I mean, consider flipping a coin for which the probability of heads is p, where p is unknown, and our goal is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and smoothing is a way of avoiding such rash conclusions. A simple smoothing method, called Laplace smoothing (or Laplace's law of succession or add-one smoothing in R&N), is to estimate p by (one plus the number of heads) / (two plus the total number of flips). Said differently, if we are keeping count of the number of heads and the number of tails, this rule is equivalent to starting each of our counts at one, rather than zero. This latter view generalizes to the case in which there is more than two possible outcomes (for instance, estimating the probability of a die coming up on each of its six faces).
Another advantage of Laplace smoothing is that it avoids estimating any probabilities to be zero, even for events never observed in the data. For HMMs, this is important since zero probabilities can be problematic for some algorithms.
So, for this assignment, you should use Laplace-smoothed estimates of probabilities. For instance, returning to the problem of estimating the probability of output o being observed in state s, you would use one plus the number of times output o appears in state s in the given data, divided by a normalization constant. (In this case, the normalization constant would be the number of times state s appears in the data, plus the total number of possible outputs. However, there is really no need to work this constant out explicitly since your code can do the normalization numerically.)
You will need to also work out Laplace-smoothed estimates for item 2, i.e., for the probability of making a transition from one state to another, as well as the probability of making a transition from the dummy start state to any of the other states.
The second part of the assignment is to write code that computes the most probable sequence of states (according to the HMM that you built from data) for a given sequence of outputs. This is essentially the problem of implementing the Viterbi algorithm as described in class and in R&N.
The second part of each of the provided datasets consists of test sequences of state-output pairs. Your Viterbi code will be provided with just the output part of each of these sequences, and from this, must compute the most likely sequence of states to produce such an output sequence. The state part of these sequences is provided so that you can compare the estimated state sequences generated by your code to the actual state sequences that generated this data. Note that these two sequences will not necessarily be identical, even if you have correctly implemented the Viterbi algorithm.
A numerical tip: the Viterbi algorithm involves multiplying many probabilities together. Since each of these numbers is smaller than one (possibly much smaller), you can end up working with numbers that are tiny enough to be indistinguishable from zero by a real computer. To avoid this problem, it is recommended that you work with log probabilities. So, rather than multiplying two probabilities p and q, simply add their logarithms using the rule
log(pq) = log(p) + log(q).
You will probably find that there is never a need to store or manipulate actual probabilities; instead, everything can be done using log probabilities.
We are providing data for three problems that HMMs can be used to solve:
For each of these problems, you should run your program and examine the results, exploring how, why and when it works. Then you should write up briefly (say, in 1-3 paragraphs for each problem) what you found. Your write-up should include any observations you may have made about how well HMMs work on these problems and why. Your observations can be quantitative (for instance, the number of errors was x) or anecdotal (for instance, the method worked really well at correcting these typos, but not these other ones). You might take anecdotal observations as a starting point for making some particular quantitative measurement (for instance, after noticing that the method seems to fail in particular situations, you might want to write a program that will systematically check if this is indeed the case). Be critical and objective, pointing out both successes and failures. Try to think of plausible explanations for your observations, and in the case of failures, try to think of modifications of our approach that might lead to greater success.
Although this write-up is quite open ended, you should be sure to discuss the following: What probabilistic assumptions are we making about the nature of the data in using a hidden Markov model? How well do those assumptions match the actual process generating the data? And to what extent was or was not performance hurt by making such realistic or unrealistic assumptions?
If you do the optional part of this assignment, your write-up should incorporate observations on the use of second-order Markov models. (Even if you don't do the optional part, you might want to speculate in your write-up why second-order Markov models might or might not improve performance.)
Toy robot
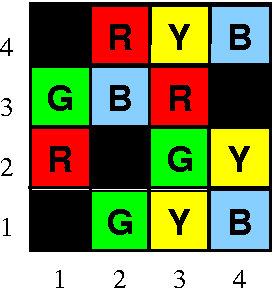
In problem 1, a robot is wandering through the following small world:
The robot can only occupy the colored squares. At each time step, the robot attempts to move up, down, left or right, where the choice of direction is made at random. If the robot attempts to move onto a black square, or to leave the confines of its world, its action has no effect and it does not move at all. The robot can only sense the color of the square it occupies. However, its sensors are only 90% accurate, meaning that 10% of the time, it perceives a random color rather than the true color of the currently occupied square. The robot begins each walk in a randomly chosen colored square.
In this problem, state refers to the location of the robot in the world in x:y coordinates, and output refers to a perceived color (r, g, b or y). Thus, a typical random walk looks like this:
3:3 r
3:3 r
3:4 y
2:4 b
3:4 y
3:3 r
2:3 b
1:3 g
2:3 b
2:4 r
3:4 y
4:4 y
Here, the robot begins in square 3:3 perceiving red, attempts to make an illegal move (to the right), so stays in 3:3, still perceiving red. On the next step, the robot moves up to 3:4 perceiving yellow, then left to 2:4 perceiving blue (erroneously), and so on.
By running your program on this problem, you will build an HMM model of this world. Then, given only sensor information (i.e., a sequence of colors), your program will re-construct an estimate of the actual path taken by the robot through its world.
The data for this problem is in robot_no_momentum.data, a file containing 200 training sequences (random walks) and 200 test sequences, each sequence consisting of 200 steps.
We also are providing data on a variant of this problem in which the robot's actions have "momentum" meaning that, at each time step, with 85% probability, the robot continues to move in the direction of the last move. So, if the robot moved (successfully) to the left on the last move, then with 85% probability, it will again attempt to move left. If the robot's last action was unsuccessful, then the robot reverts to choosing an action at random. Data for this problem is in robot_with_momentum.data.
Correcting typos without a dictionary
Problem 2 deals with the problem of correcting typos in text without using a dictionary. Here, you will be given text containing many typographical errors and the goal is to correct as many typos as possible.
In this problem, state refers to the correct letter that should have been typed, and output refers to the actual letter that was typed. Given a sequence of outputs (i.e., actually typed letters), the problem is to reconstruct the hidden state sequence (i.e., the intended sequence of letters). Thus, data for this problem looks like this:
i i
n n
t t
r r
o o
d x
u u
c c
t t
i i
o i
n n
_ _
t t
h h
e e
_ _
where the left column is the correct text and the right column contains text with errors.
Data for this problem was generated as follows: we started with a text document, in this case, the Unabomber's Manifesto, which was chosen not for political reasons, but for its convenience being available on-line and of about the right length. For simplicity, all numbers and punctuation were converted to white space and all letters converted to lower case. The remaining text is a sequence only over the lower case letters and the space character, represented in the data files by an underscore character. Next, typos were artificially added to the data as follows: with 90% probability, the correct letter is transcribed, but with 10% probability, a randomly chosen neighbor (on an ordinary physical keyboard) of the letter is transcribed instead. Space characters are always transcribed correctly. In a harder variant of the problem, the rate of errors is increased to 20%. The first (roughly) 20,000 characters of the document have been set aside for testing. The remaining 161,000 characters are used for training.
As an example, the original document begins:
introduction the industrial revolution and its consequences have been a disaster for the human race they have greatly increased the life expectancy of those of us who live in advanced countries but they have destabilized society have made life unfulfilling have subjected human beings to indignities have led to widespread psychological suffering in the third world to physical suffering as well and have inflicted severe damage on the natural world the continued development of technology will worsen the situation it will certainly subject human beings to greater indignities and inflict greater damage on the natural world it will probably lead to greater social disruption and psychological suffering and it may lead to increased physical suffering even in advanced countries the industrial technological system may survive or it may break down if it survives it may eventually achieve a low level of physical and psychological suffering but only after passing through a long and very painful period of adjustment and only at the cost of permanently reducing human beings and many other living organisms to engineered products and mere cogs in the social machine
With 20% noise, it looks like this:
introductipn the industfial revolhtjon and its consequences bafw newn a diszster rkr the yumab race thdy have grwatky increased the ljte esoectandy od thosr of is who libe in advanced coubfries but they have fewtabipuzee xociwty have made life ujfuorillkng have wubjwdted humah beints to incihbjtids have led to qidespreze lsyxhllotical shffeding kn tne third wkrld to phyxicql sufcefimg as weol and hqve ingoidtex srvere damsge on the natural world the confinued developmeng of twvhjllogy will wotsen thd situation it wull certaknly sunjrct yyman beingw tl greater ibdignities snd infpixt greagwr damsge on fhe natural alrld it wjlk probably lwad tk grezter sofiqp disrupgiln and pstchokofucal wufterkng anc it may kead fl uncreqxed pgusiczl sucfreinh even in acgajved countries the indhsteial tedhnologicak system may survivr or ut nay brezk down uf it survives it nay evenyuakly achieve a los lwvel of phyxkcal and psycyoligical sufveribg but only after passing theough a long amd very painful periox od adjuwtmebt and only at the fost kf permsnently reducing hymaj veings abs nsjy otgwr kuving orbanisms to envineered leoduxfs amd mere clgs in thr soxiap maxhjne
The error rate (fraction of characters that are mistyped) is about 16.5% (less than 20% because space characters were not corrupted).
The text reconstructed using an HMM with the Viterbi algorithm looks like this:
introduction the industrial revoluthon and its consequences bare neen a dissster ror the tuman race they have greatly increased the lite esoectandy od those of is who libe in advanced counfries but they have festabupusee cocisty have made live intiorilling have wibjested human beints to incingitids have led to widesprese lsysullotical suffeding in the third world to physical surcefing as weol and have ingoistes severe damage on the natural world the continued developmeng of techillogy will wotsen the situation it will certaknly sunirct tyman beinge tl greater indithities and infoist greager damage on the natural aleld it will probably owad to grester sofial distuption and pstchomofucal wiftering and it may kead fl increqxed ogusical suctreing even in achanved countries the industeial technologicak system may survive or ut nay break down if it survives it nay eventually achieve a los level of physical and psycholigical survering but only arter passing theough a long and very paindul perios od adjustment and only at the fost of permanently reducing human veings ans nany other kiving organisms to envineered leodusts and mere clys in the social machine
The error rate has dropped to about 10.4%.
If you do the extra credit part of this assignment which involves building a second-order Markov process, you will get reconstructed text that looks like this:
introduction the industrial revolution and its consequences have neen a disaster for the human race they have greatly increased the lite expectandy of those of is who live in advanced coubtries but they have restabilized society have made life untiorilling have subjected human beints to incihbuties have led to widesprese psychological suffering in the third world to physical suffering as well and have ingoisted severe damage on the natural world the confinued developmeng of technology will witsen the situation it will certainly subject human beinge to greater indignities and inflist greater damage on the natural alrld it will probably lead to greater social disruption and psychological suffering and it may lead to uncreased physical suffering even in actaived countries the industrial technological system may survive or it may break down if it survives it may eventually achieve a lis level of physical and psychological suffering but only after passing through a long and very painful perild of adjuwtment and only at the fost of permanently reducing human beings ans many other living organisms to envineered produsts and mere clgs in the social machine
The error rate now has dropped even further to about 5.8%.
Data for this part of the assignment is in typos10.data and typos20.data, representing data generated with a 10% or 20% error rate, respectively.
Tracking a changing topic
Problem 3 deals with the problem of tracking a changing topic, for instance, in a conversation or while watching the news. Your program will be provided with a stream of words, first on one topic, then on another topic, and so on. The goal is to segment the stream of text into blocks, and to identify the topic of each of these blocks. There are six possible topics, namely, baseball, cars, guns, medicine, religion and windows (as in Microsoft). A state in this problem is an underlying topic. An output is an actual word appearing in the text. So for instance, data might look like this:
baseball when
baseball are
baseball the
baseball yankees
baseball planning
baseball on
baseball activating
baseball melido
baseball perez
medicine one
medicine of
medicine my
medicine friends
medicine has
medicine had
medicine to
medicine go
medicine to
medicine the
medicine doctor
medicine because
medicine he
medicine had
medicine chest
medicine pains
guns what
guns to
guns do
guns if
guns you
guns shoot
guns somebody
To simplify the data file, lines on which the output changes but not the state can be combined. Thus, in terms of coding the data, the above data is exactly equivalent to the following:
baseball when are the yankees planning on activating melido perez
medicine one of my friends has had to go to the doctor
medicine because he had chest pains
guns what to do if you shoot somebody
Note that there are many possible outputs for this problem, essentially one for every word. Your code should be efficient enough to handle such a large number of possible outputs.
Data for this problem was created as follows: the bodies of 5302 articles were collected from six newsgroups (namely, rec.sports.baseball, rec.auto, talk.politics.guns, sci.med, talk.religion.misc and comp.os.ms-windows.misc) corresponding to the six topics. All punctuation was removed (converted to white space) and all letters converted to lower case. The articles were then randomly permuted and concatenated together forming a sequence of states (topics) and outputs (words). 1500 articles were saved for use in testing, the rest for training.
Using an HMM with the Viterbi algorithm on this data will produce a sequence of topics attached to each of the words. For instance, in the case above, we might get something like the following (I made this up -- this is not based on an actual run):
baseball when
baseball are
baseball the
baseball yankees
baseball planning
baseball on
baseball activating
baseball melido
baseball perez
baseball one
baseball of
baseball my
baseball friends
medicine has
medicine had
medicine to
medicine go
medicine to
medicine the
medicine doctor
medicine because
medicine he
medicine had
guns chest
guns pains
guns what
guns to
guns do
guns if
guns you
guns shoot
guns somebody
This corresponds to breaking up the text (rather imperfectly) into three blocks: "when are the yankees planning on activating melido perez one of my friends" with topic baseball; "has had to go to the doctor because he had" with topic medicine; and "chest pains what to do if you shoot somebody" with topic guns.
Data for this part of the problem is in the file topics.data.
For extra credit, you can redo the entire assignment using a second-order Markov model. Recall that in such a model, the next state depends not only on the current state, but also on the last state. Thus, X[t+1] depends both on X[t] and on X[t-1]. (However, the evidence E[t] still depends only on the current state X[t].) These models are described in R&N. You will need to modify your representation of an HMM, and you will also need to modify the Viterbi algorithm. Your implementation should be fast enough for us to test on the kind of data provided in a reasonable amount of time. For this optional part of the assignment, you should also run your second-order model on some of the datasets and comment on its performance in your write-up.
We are providing a class called DataSet that loads data from a file and stores it in a number of data structures available as public fields of the class. The class has a constructor taking a file name as argument that reads in the data from the file. Each state is represented by an integer in the range 0 (inclusive) to numStates (exclusive), where numStates is the total number of states. (These do not include the dummy start state.) Outputs are represented in a similar fashion. The stateName and outputName arrays convert these integers back to strings in the obvious fashion. The array of arrays trainState represents the set of sequences of states observed during training. Thus, trainState[i][j] is the value of the j-th state in the i-th training sequence. Similarly for trainOutput, testState and testOutput.
Data files consist of one or more sequences of training state-output pairs, followed by one or more sequences of testing state-output pairs. Each sequence is separated by a line consisting of a single period. Training and testing data are separated by a line consisting of two periods. For instance, here is a simple, sample file:
a 0
b 1 0 0
a 1
.
a 1 1
..
b 0 1
a 1
.
a 0
a 0
In this tiny example, there are two states, a and b, and two outputs 0 and 1. There are two training sequences: (a,0),(b,1),(b,0),(b,0),(a,1) and (a,1),(a,1). There are two test sequences: (b,0),(b,1),(a,1) and (a,0),(a,0).
We also are providing a class called Test consisting only of a main. This file is provided as a starting point for testing your code. You will probably want to modify this file, or write your own. Running Test will call the DataSet constructor with the file name provided on the command line; will then use the data in this file to create an HMM (using your code); will print out the HMM (unless it is too big); and will finally call your code to compute the most likely state sequence on each of the test output sequences.
If run on the sample file above, the output would look like this:
Start probabilities:
a : .750
b : .250
Transition probabilities:
a b
a : .500 .500
b : .400 .600
Output probabilities:
0 1
a : .333 .667
b : .600 .400
sequence 0:
b a 0
b a 1
a a 1
errors: 2 / 3 = 0.6666666666666666
sequence 1:
a a 0
a b 0
errors: 1 / 2 = 0.5
The first table shows the probability of a transition from the dummy start state to each of the states (in this case, a and b). The second table shows the probability of transitioning from each state to every other state. The third table shows the probability of each output being observed in each state. Finally, each test sequence is printed. The first column shows the correct state; the second column shows the state sequence estimated by your code; the third column shows the output sequence. Finally the number of errors (where columns one and two disagree) is printed.
To debug your code, you will surely want to run it on small data files of this kind before running on the large datasets provided. Also, when running on large datasets, you may need to increase the maximum heap size allocated to your program. This option is platform dependent (use the -X option to find out what it is on yours), but often is something like -Xmx512M, which will give your program access to 512MB of memory.
Your job is to fill in the constructor and all of the methods in the template Hmm.java file that is being provided. Part 1 of this assignment belongs in the buildFromData method. Part 2 goes in the mostLikelySequence method. There are other simple methods in this template that you also need to write for probing the HMM. In addition, you need to write a method buildFromTable which builds an HMM with a specified set of probabilities. This should be simple to write. We are asking you to write these latter methods so that we can effectively and automatically test your code.
If you are doing the optional part of this assignment, you also should write a class Hmm2.java. This class should include a constructor, and the methods buildFromData and mostLikelySequence with signatures identical to those in Hmm.java. However, you do not need to provide any of the other methods.
The final code that you turn in should not write anything to standard output or standard error.
All code and data files can be obtained from this directory, or all at once from this tar file. Documentation is available here.
Using whiteboard, you should turn in the following:
In addition, you should turn in your write-up exploring the provided datasets as described above. This written work should be handed in with the written exercises.
We will automatically test your Hmm code on data similar (but not identical) to the data provided with this assignment. Your grade will depend largely on getting the right answers. In addition, your code should be efficient enough to run reasonably fast (easily under a minute on each of the provided data sets on a 2.4GHz machine), and should not terminate prematurely with an exception (unless given bad data, of course); code that does otherwise risks getting no credit for the automatic testing portion of the grade. As usual, you should follow good programming practices, including documenting your code.
Your write-up should be clear, concise, thoughtful, critical and perceptive.
This programming assignment will be worth about 80 points (divided between the coding part of the assignment, and the write-up). The optional component will be worth roughly 20-25 points.