How can interactive devices connect with users in the most immediate and intimate way? This question has driven interactive computing for decades. If we think back to the early days of computing, user and device were quite distant, often located in separate rooms. Then, in the ’70s, personal computers “moved in” with users. In the ’90s, mobile devices moved computing into users’ pockets. More recently, wearables brought computing into constant physical contact with the user’s skin. These transitions proved to be useful: moving closer to users and spending more time with them allowed devices to perceive more of the user, allowing devices to act more personal. The main question that drives my research is: what is the next logical step? How can computing devices become even more personal?
Some researchers argue that the next generation of interactive devices will move past the user’s skin, and be directly implanted inside the user’s body. This has already happened in that we have pacemakers, insulin pumps, etc. However, I argue that what we see is not devices moving towards the inside of the user’s body but towards the “interface” of the user’s body they need to address in order to perform their function.
This idea holds the key to more immediate and personal communication between device and user. The question is how to increase this immediacy? My approach is to create devices that intentionally borrow parts of the user’s body for input and output, rather than adding more technology to the body. I call this concept “devices that overlap with the user’s body”. I’ll demonstrate my work in which I explored one specific flavor of such devices, i.e., devices that
borrow the user’s muscles.
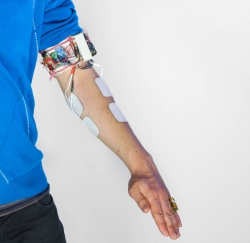
In my research I create computing devices that interact with the user by reading and controlling muscle activity. My devices are based on medical-grade signal generators and electrodes attached to the user’s skin that send electrical impulses to the user’s muscles; these impulses then cause the user’s muscles to contract. While electrical muscle stimulation (EMS) devices have been used to regenerate lost motor functions in rehabilitation medicine since the ’60s, during my PhD I explored EMS as a means for creating
interactive systems. My devices form two main categories: (1) Devices that allow users eyes-free access to information by means of their proprioceptive sense, such as a variable, a tool, or a plot. (2) Devices that increase immersion in virtual reality by simulating large forces, such as wind, physical impact, or walls and heavy objects.
Bio:
Pedro Lopes is a PhD Candidate at Prof. Baudisch’s Human Computer Interaction Lab at the Hasso Plattner Institute, Germany. Pedro’s work asks the question: what if interfaces would share part of our body? Pedro has materialized these ideas by creating interactive systems based on electrical muscle stimulation. These devices use part of the wearer’s body for output, i.e., the computer can output by actuating the user’s muscles with electrical impulses, causing it to move involuntarily. The wearer can sense the computer’s activity on their own body by means of their sense of proprioception. Pedro’s wearable systems have shown to (1) increase realism in VR, (2) provide a novel way to access information through proprioception, and (3) serve as a platform to experience and question the boundaries of our sense of agency.
Pedro’s work is published at top-tier conferences (ACM CHI &UIST) and demonstrated at venues such as ACM SIGGRAPH and IEEE Haptics. Pedro has received the ACM CHI Best Paper award for his work on Affordance++, Best Talk Awards and several nominations. As part of his research, Pedro has exhibited at Ars Electronica 2017, Science Gallery Dublin and World Economic Forum in San Francisco. His work also captured the interest of media, such as MIT Technology Review, NBC, Discovery Channel, NewScientist and Wired. (Learn more about Pedro's work here: plopes.org).
Selected Youtube links: VR Walls, Muscle Plotter, Affordance++